
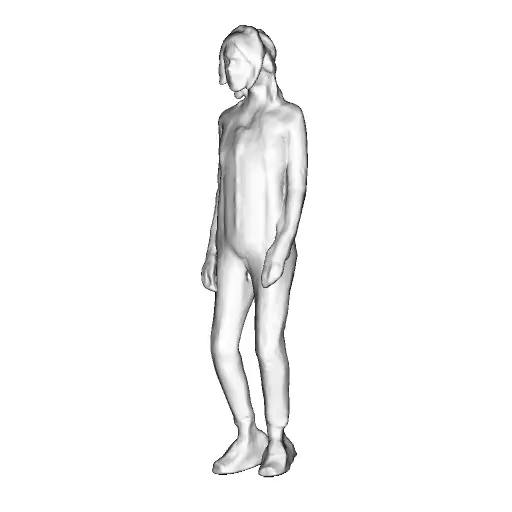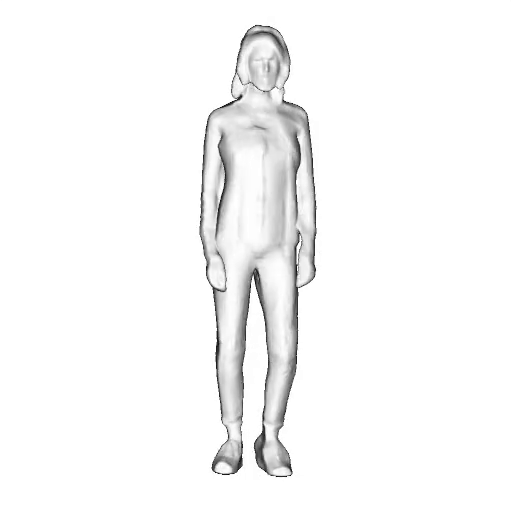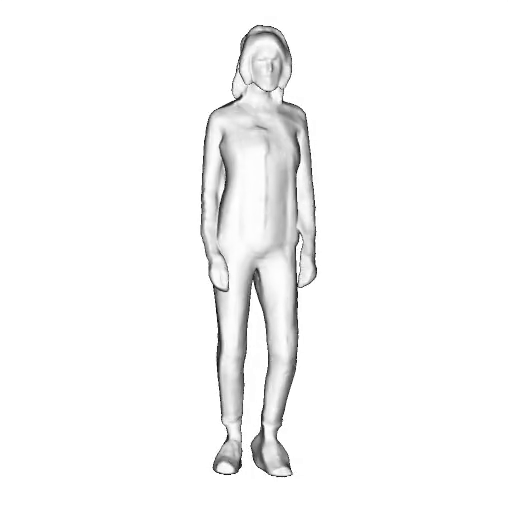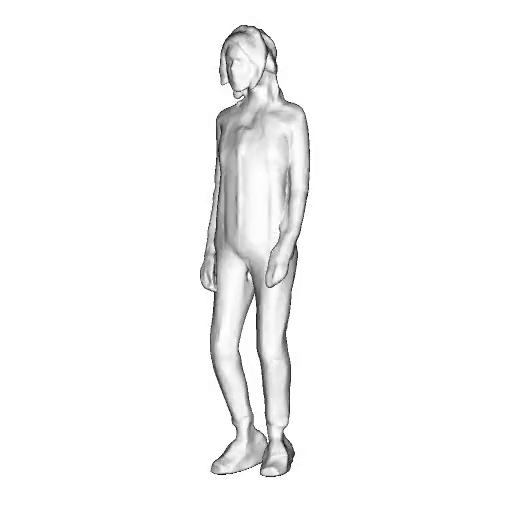
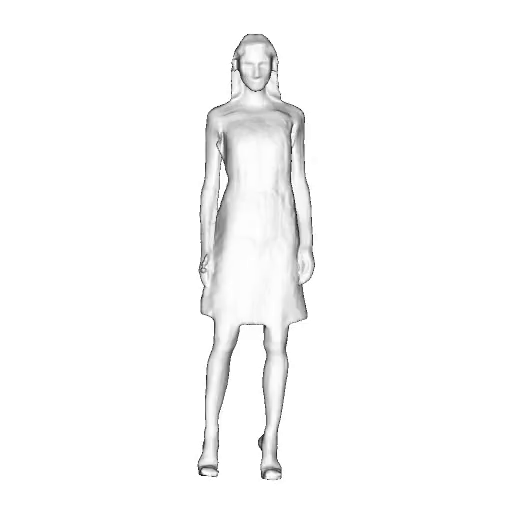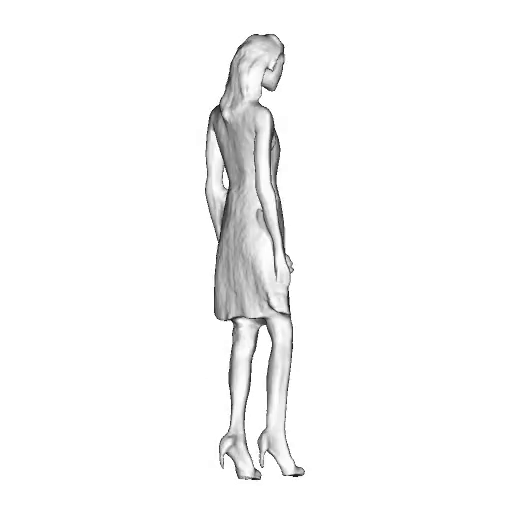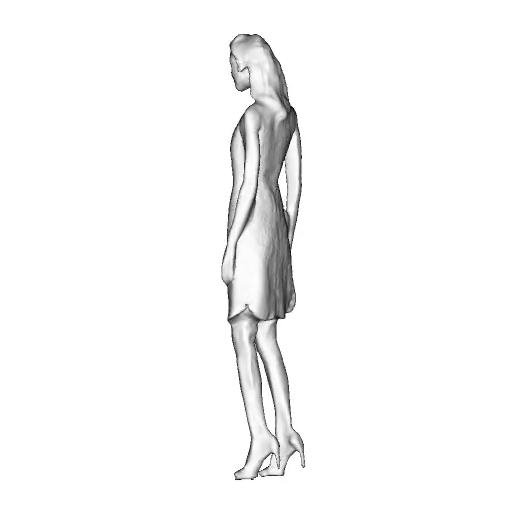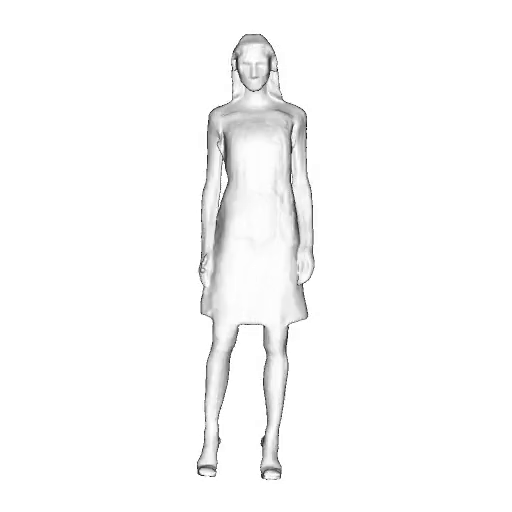
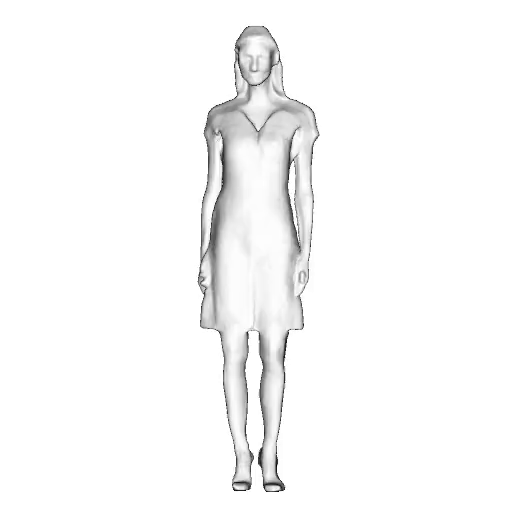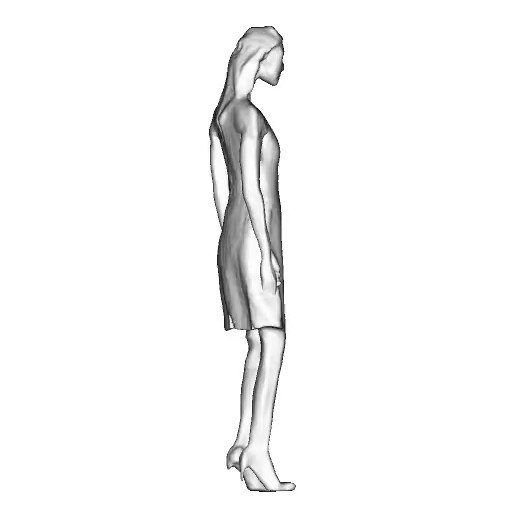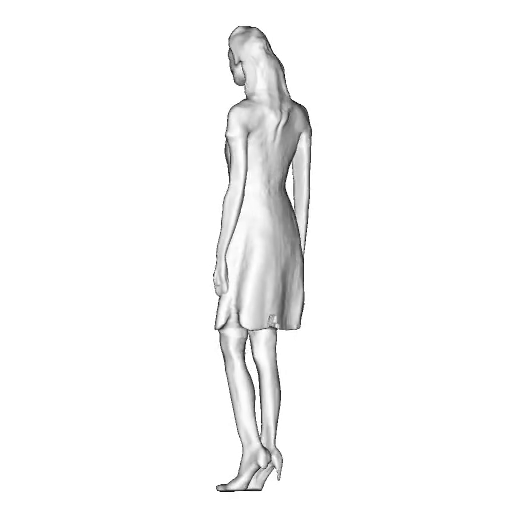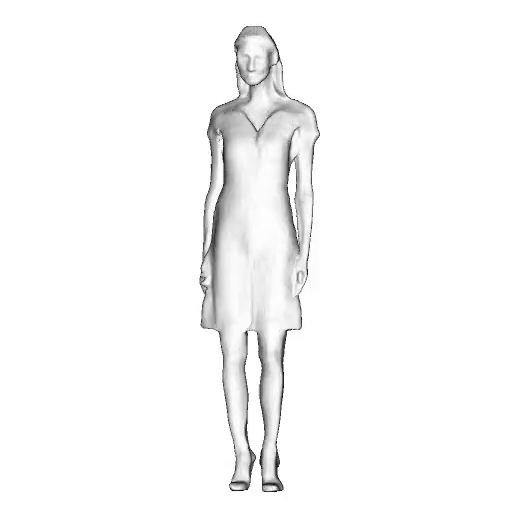
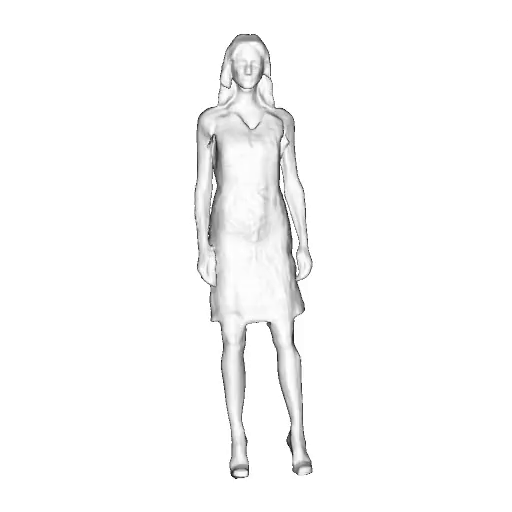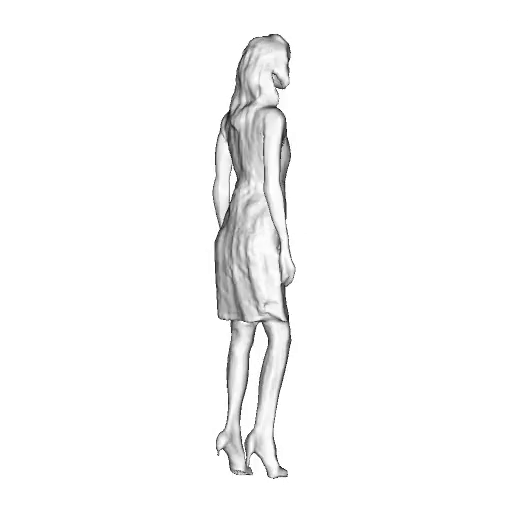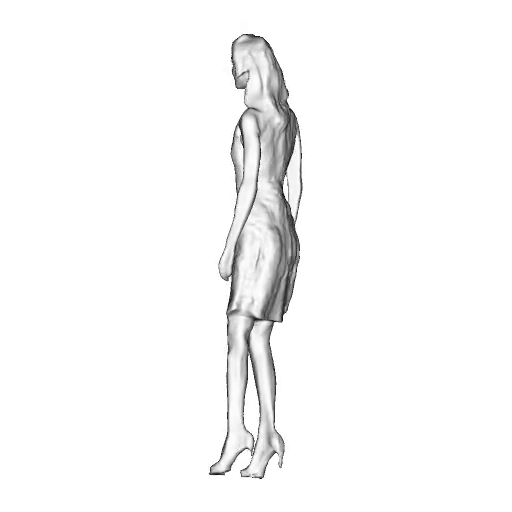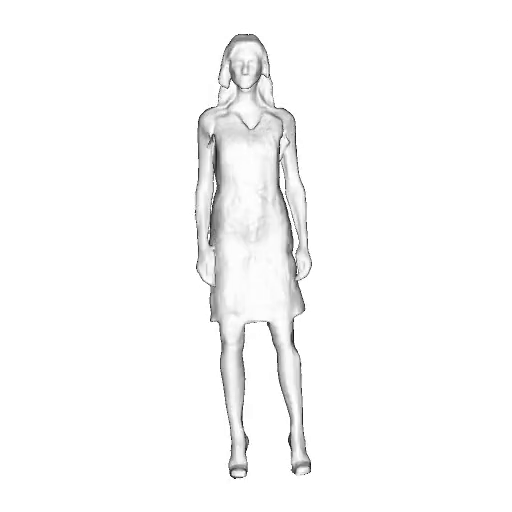
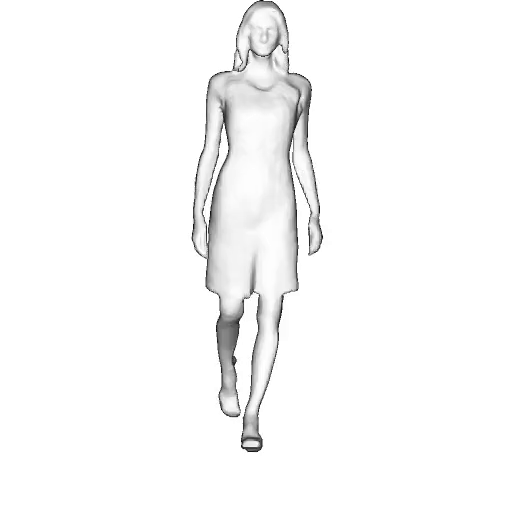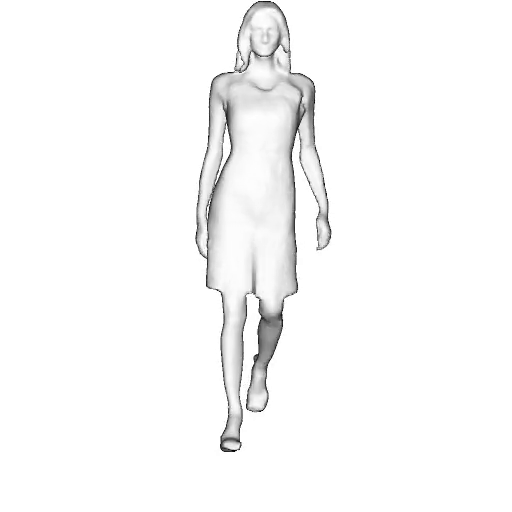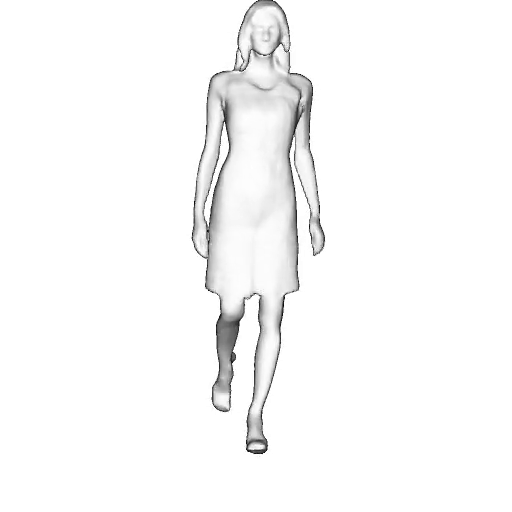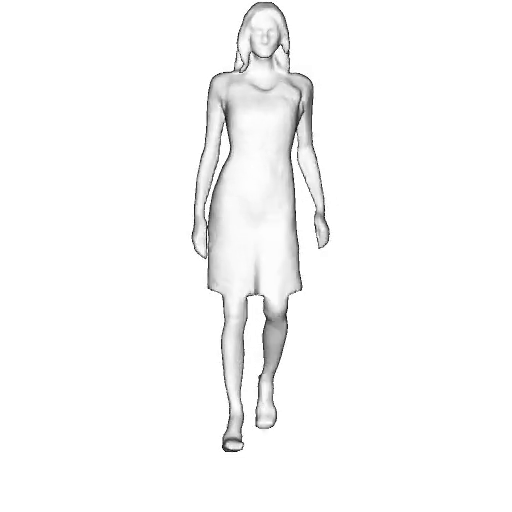
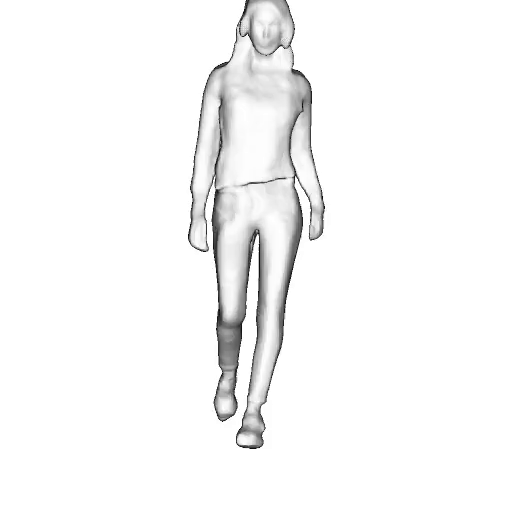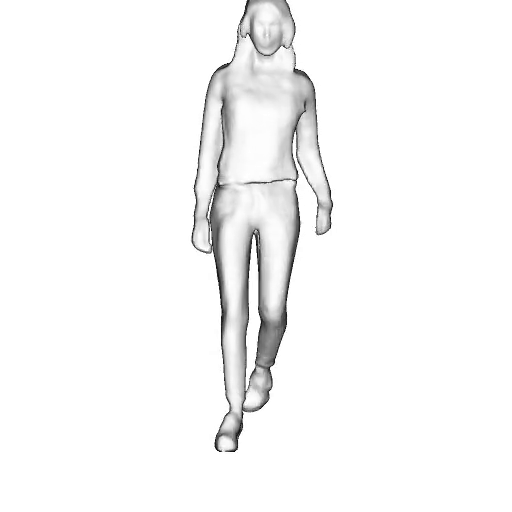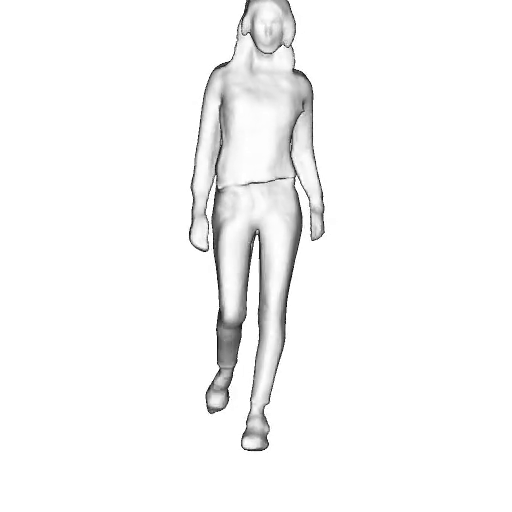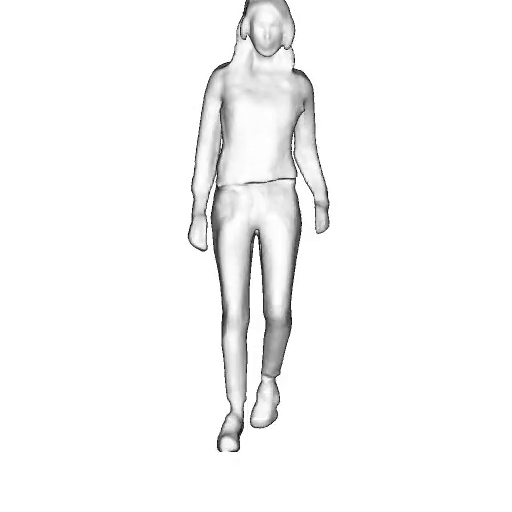
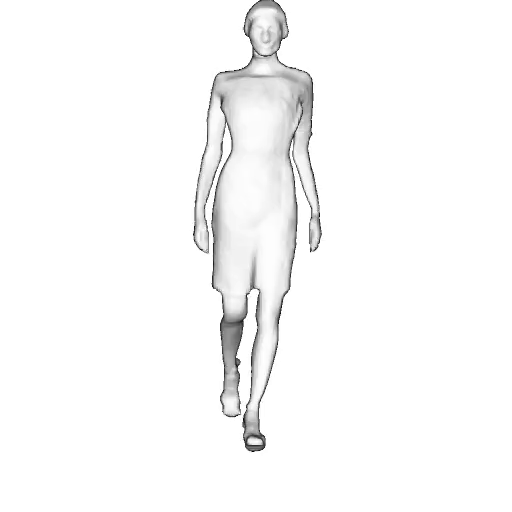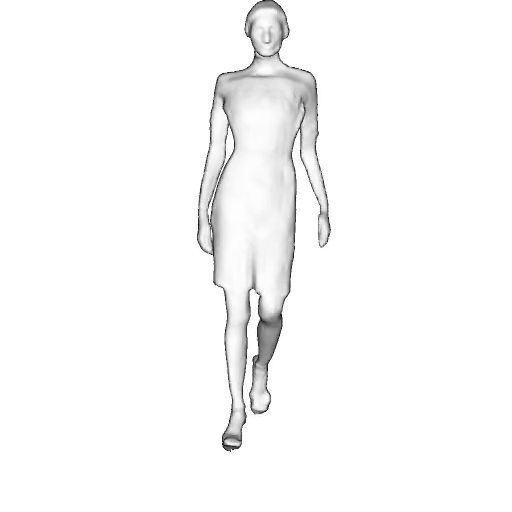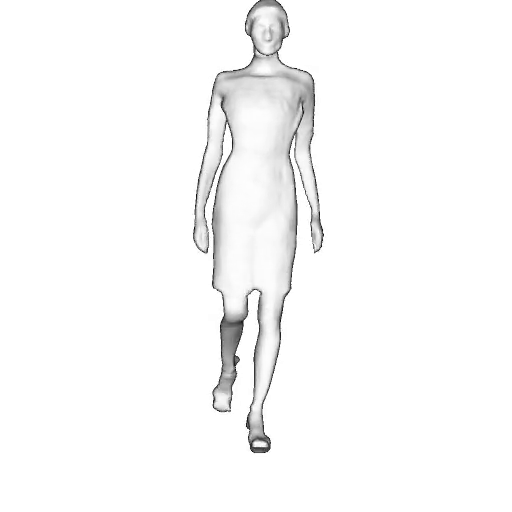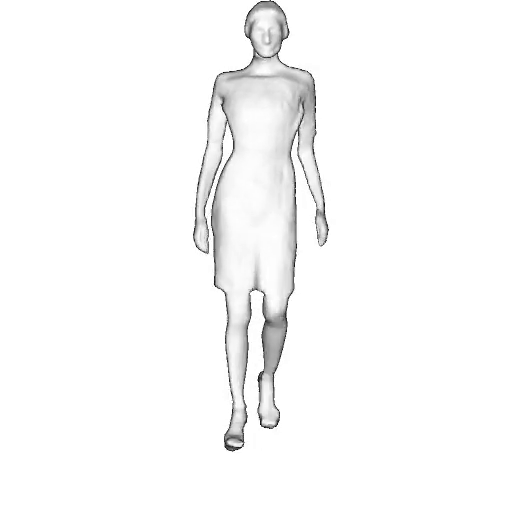
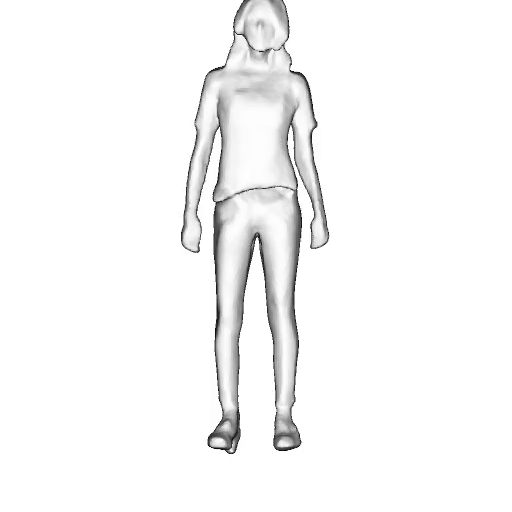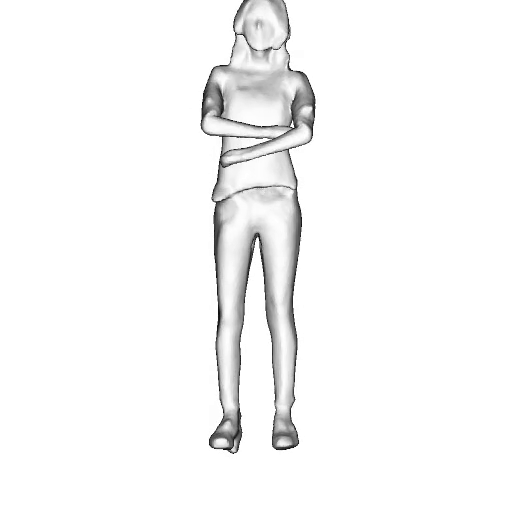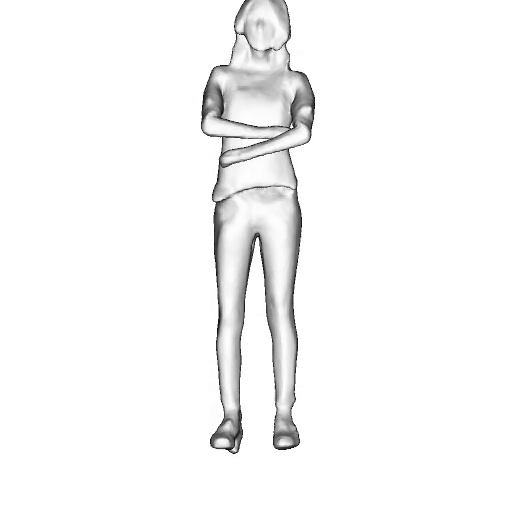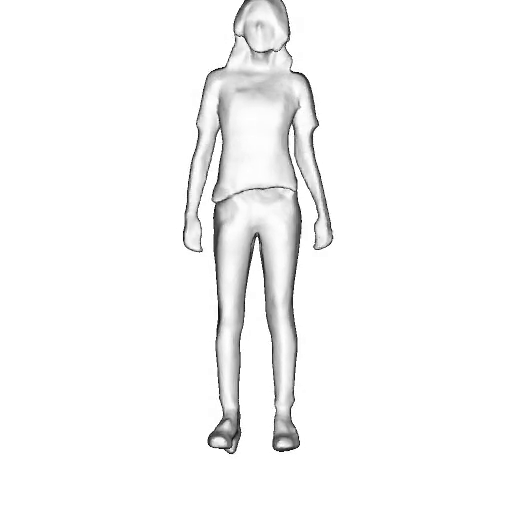
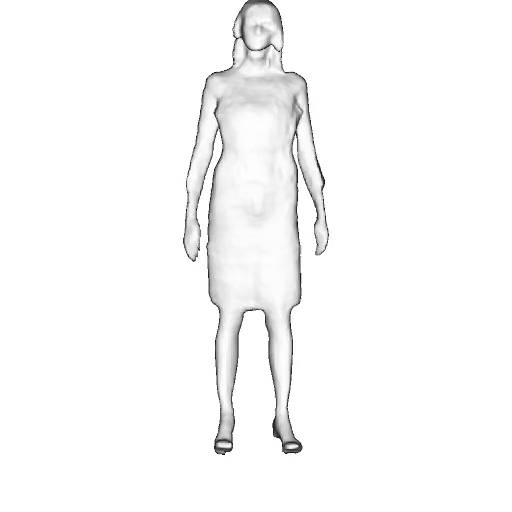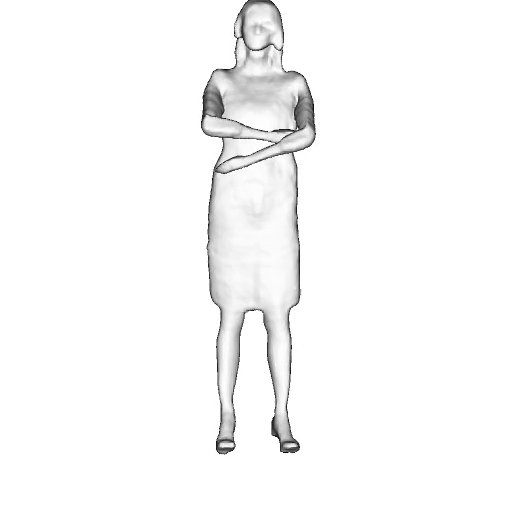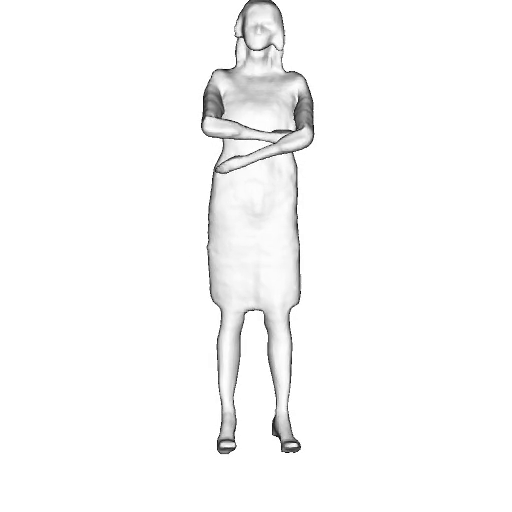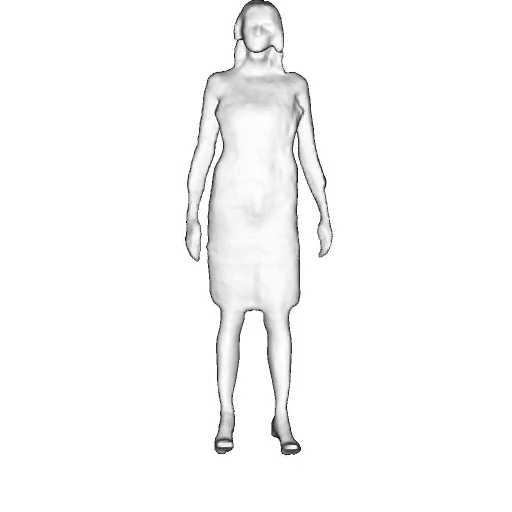
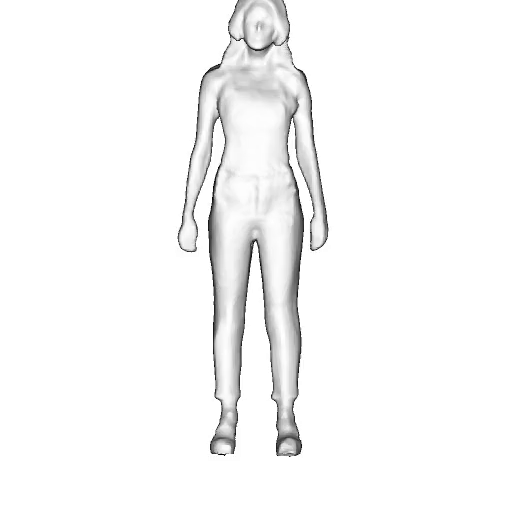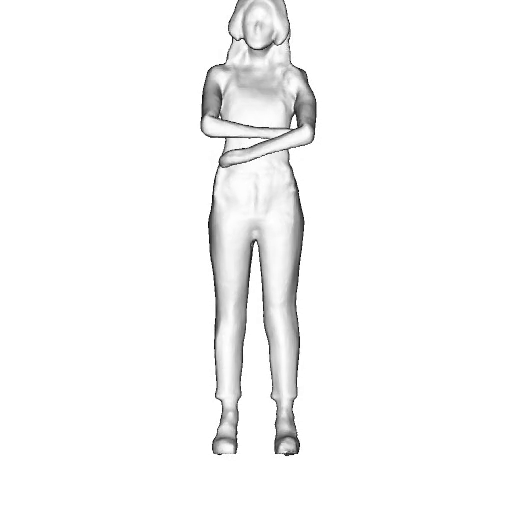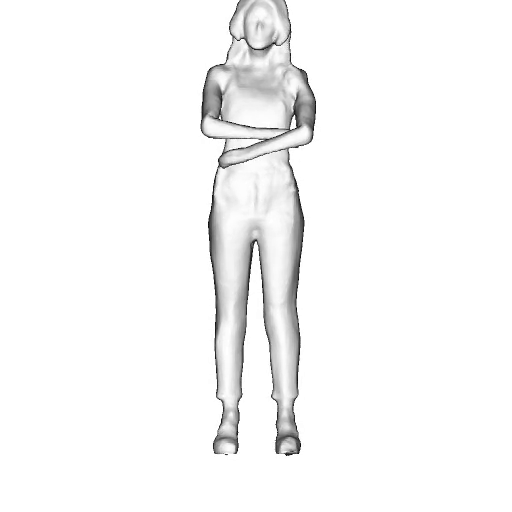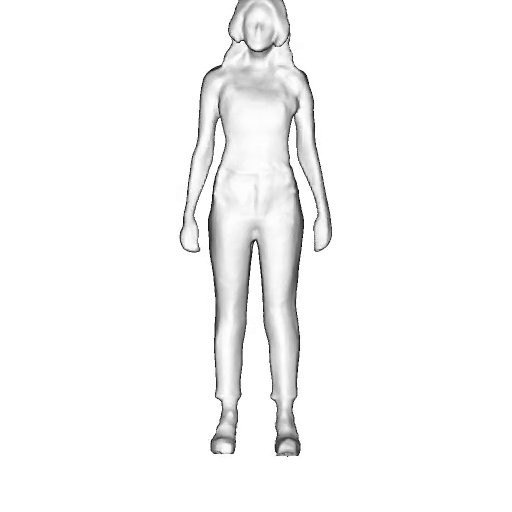
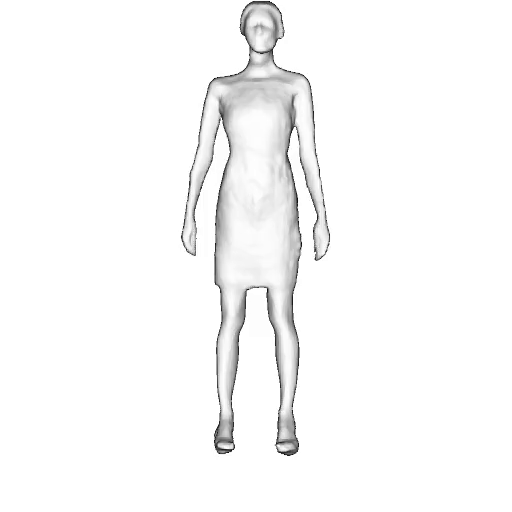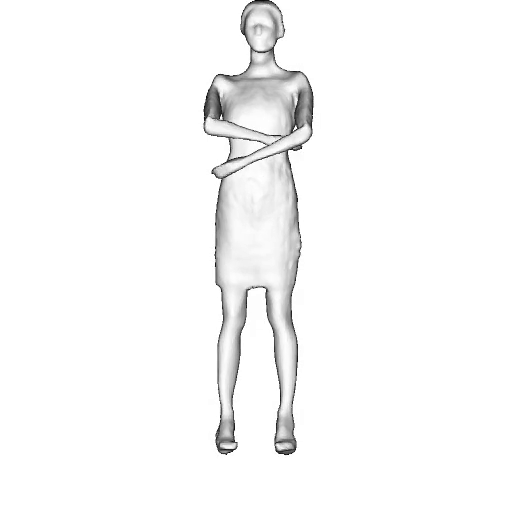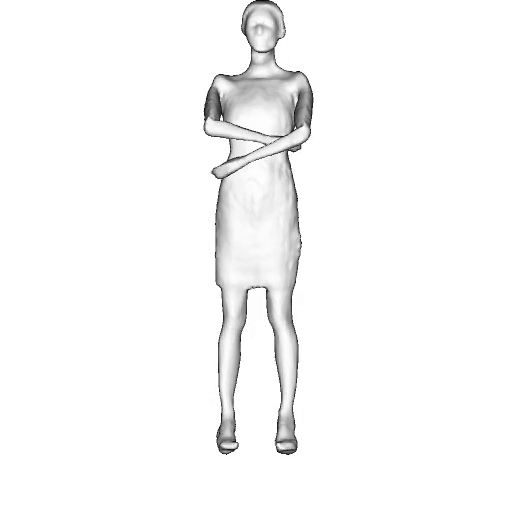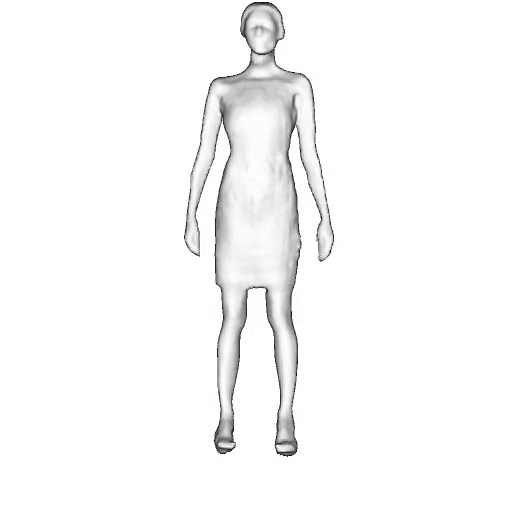
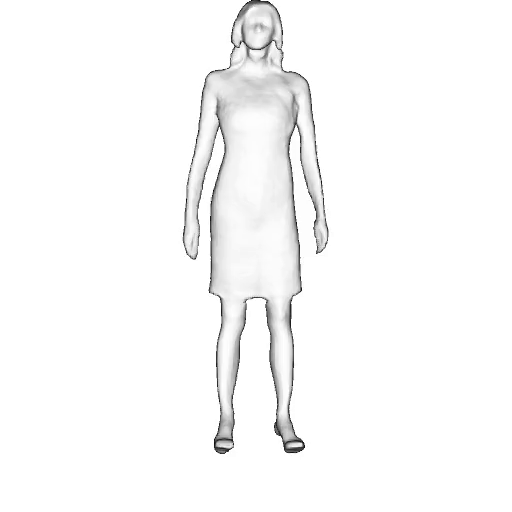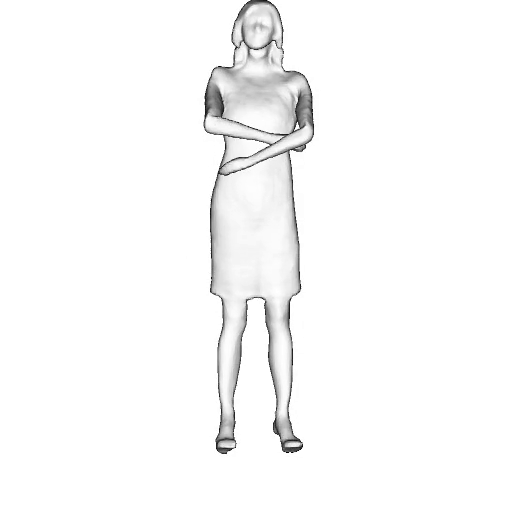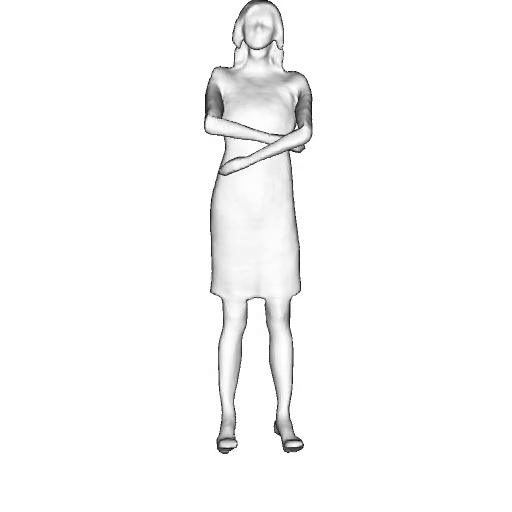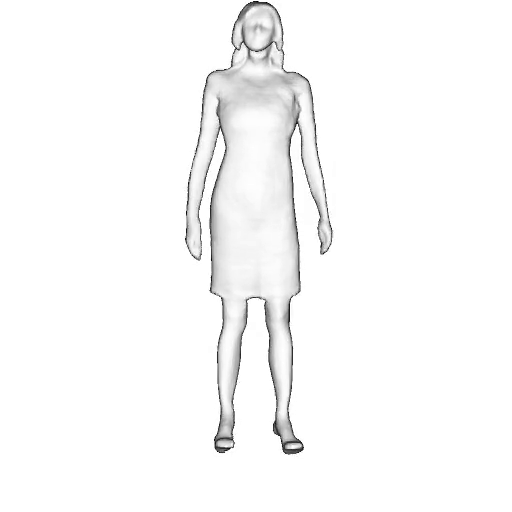
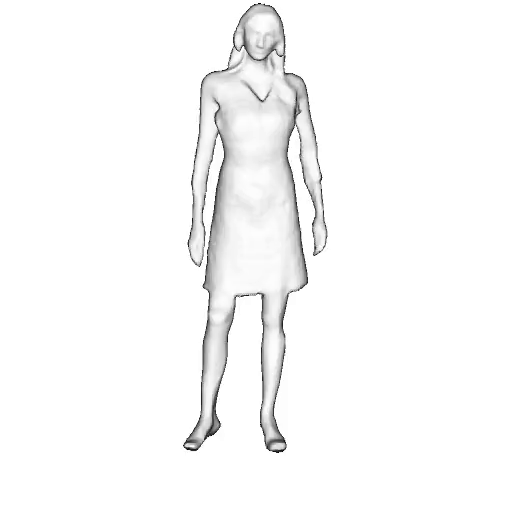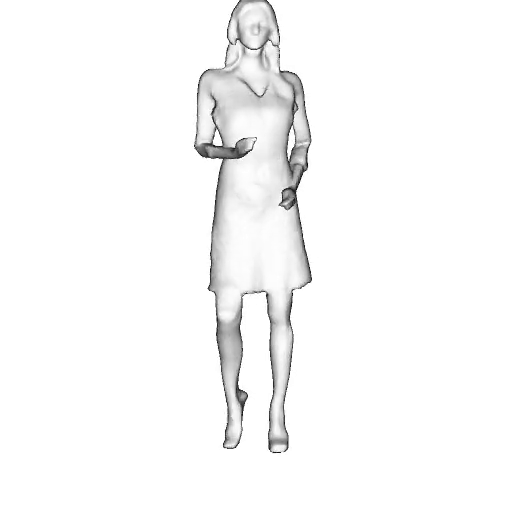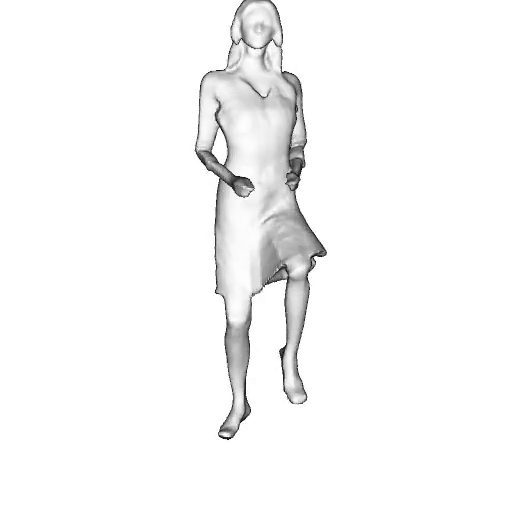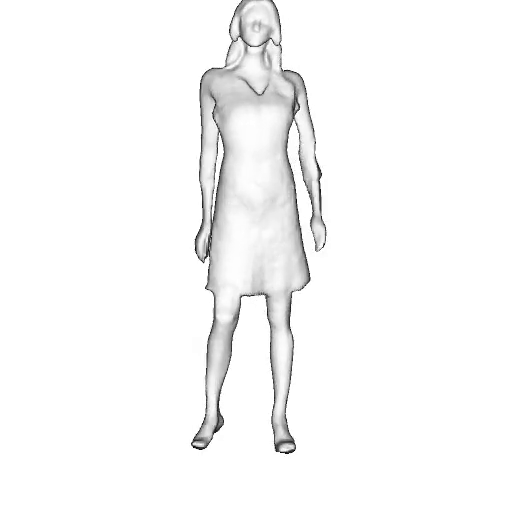
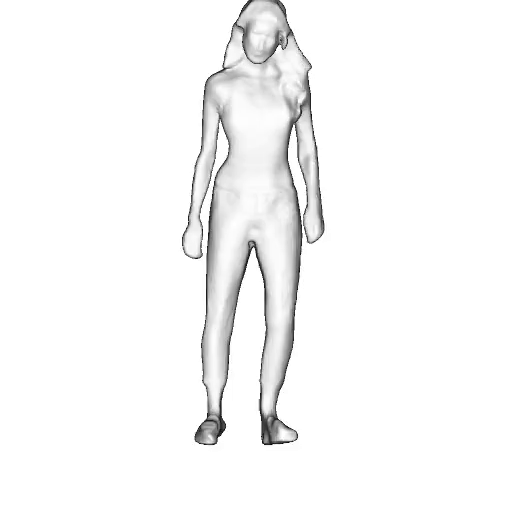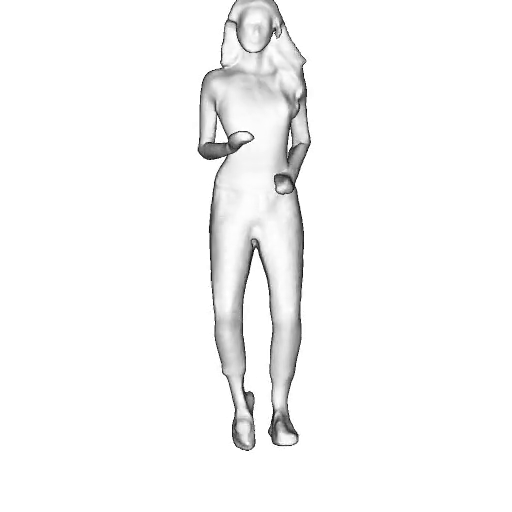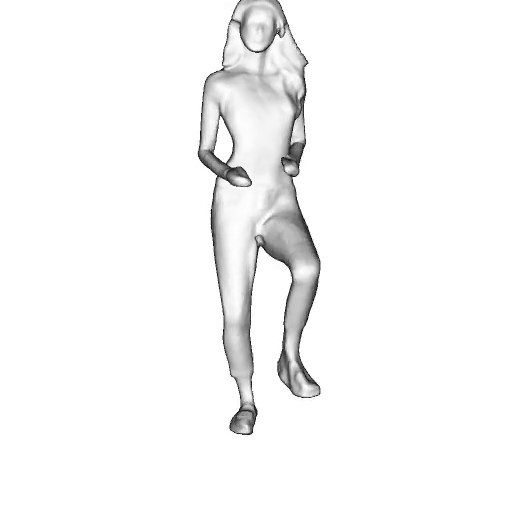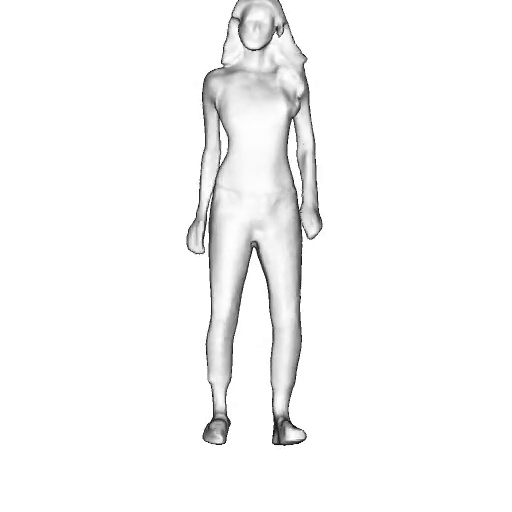
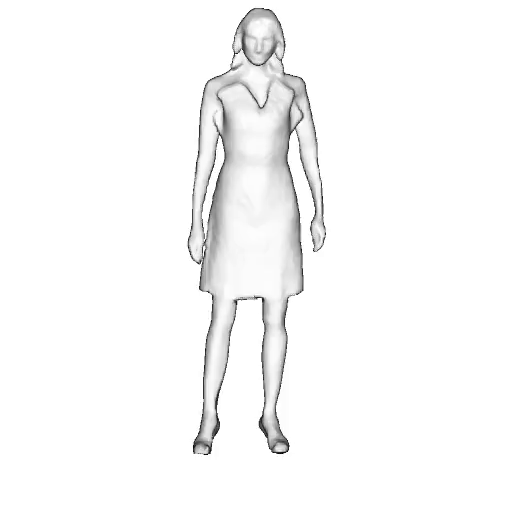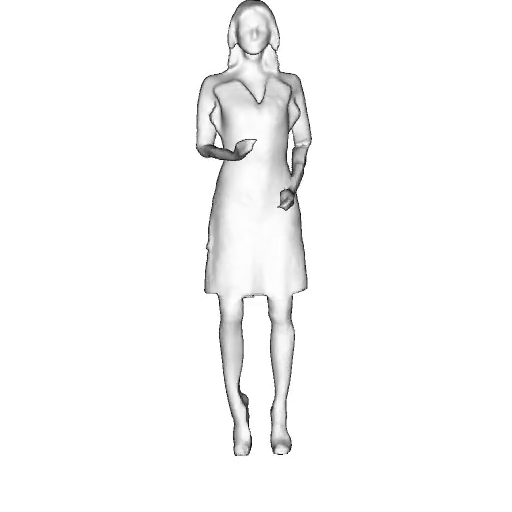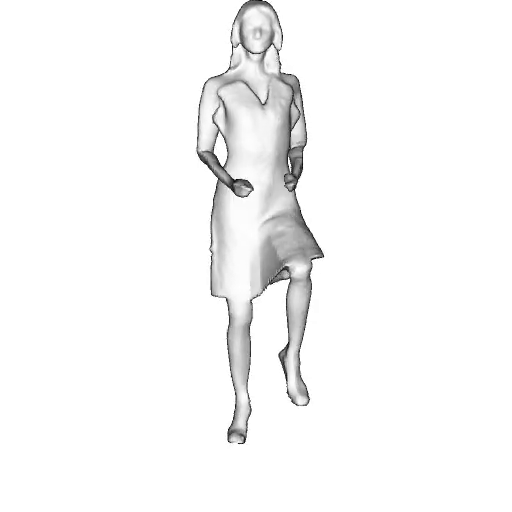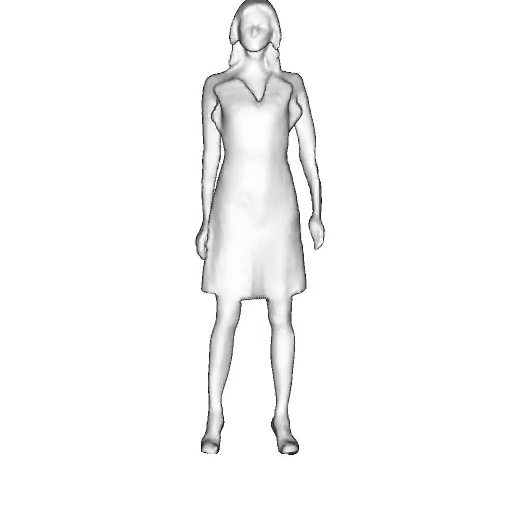
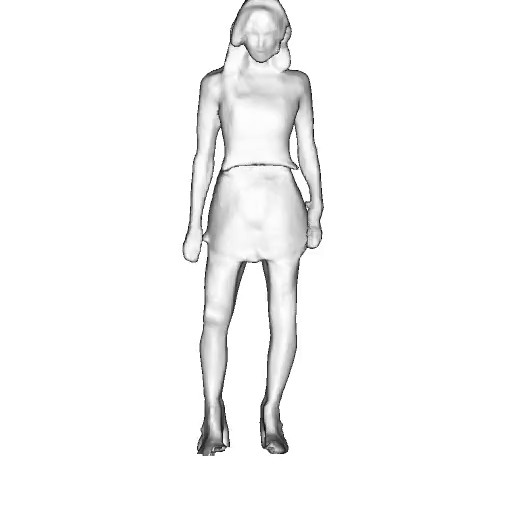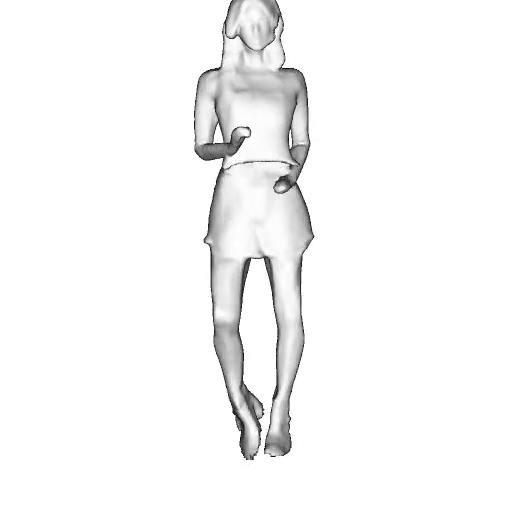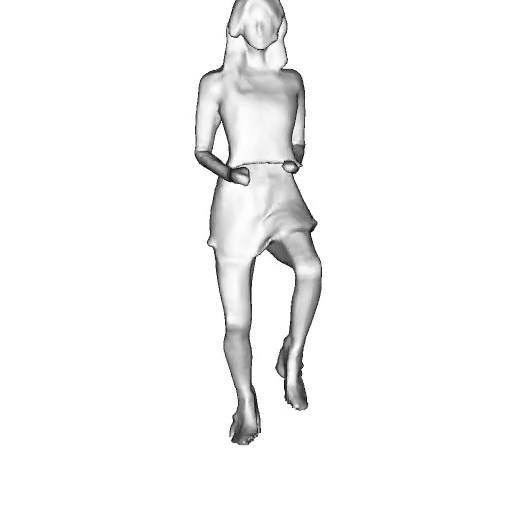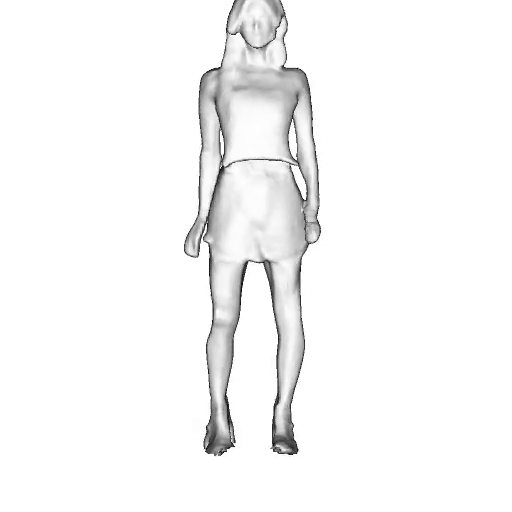
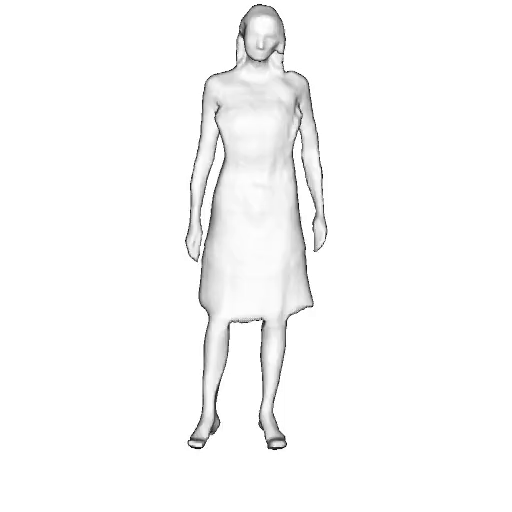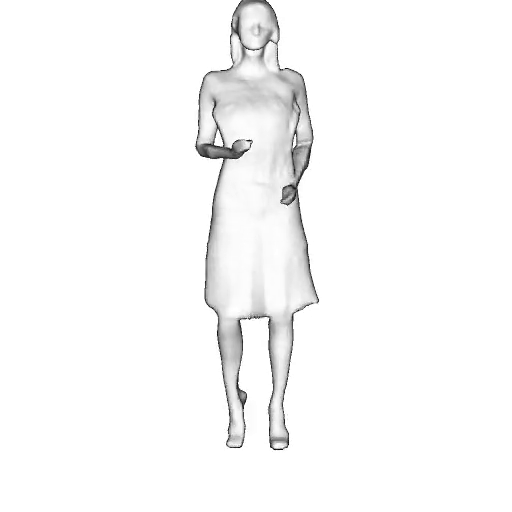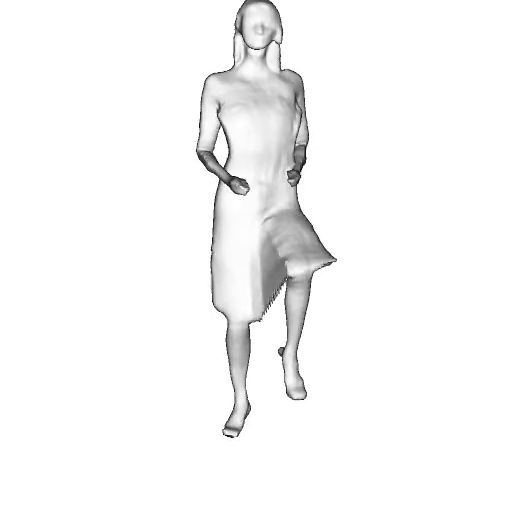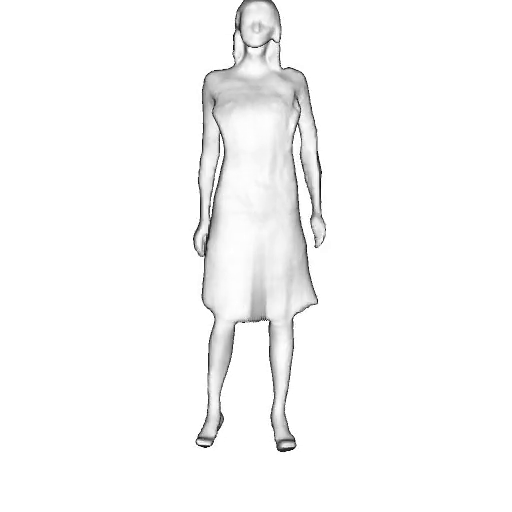
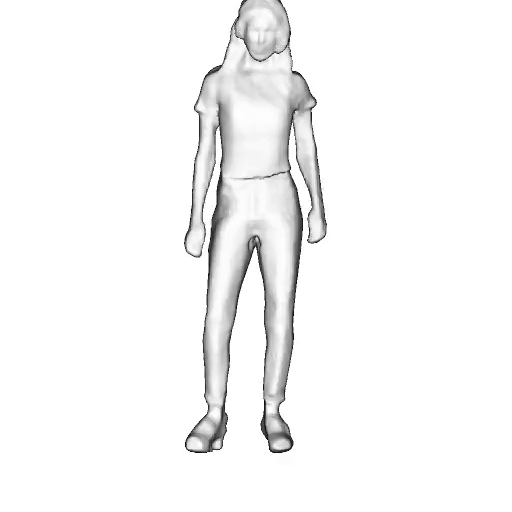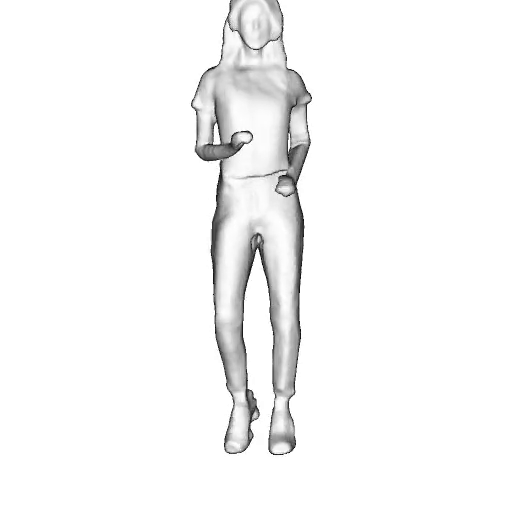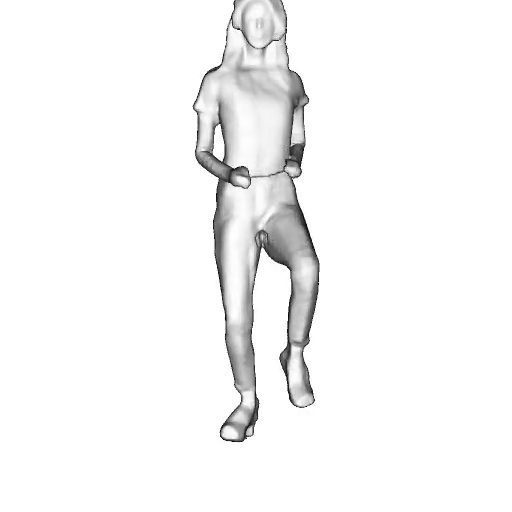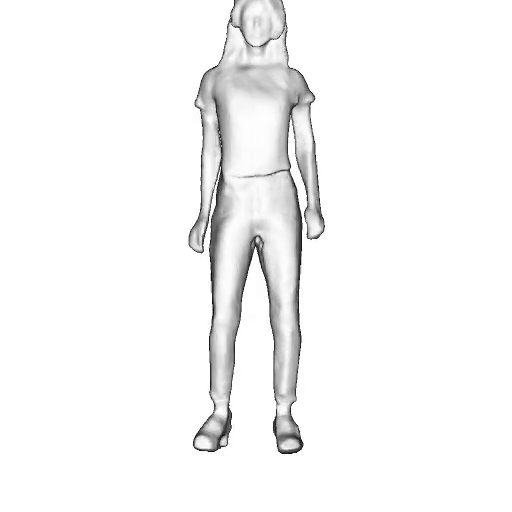
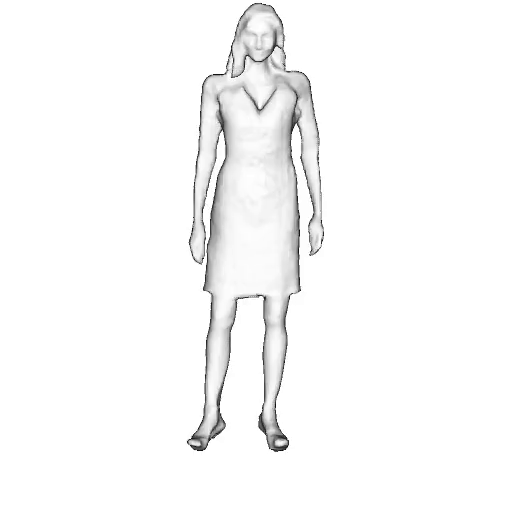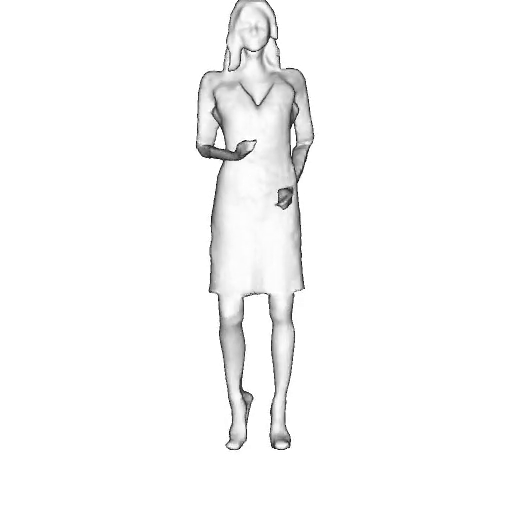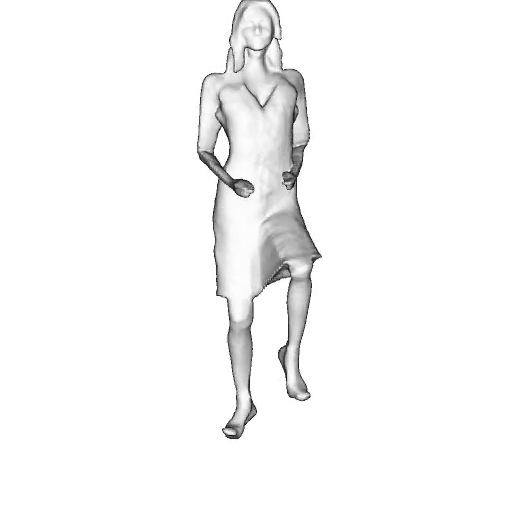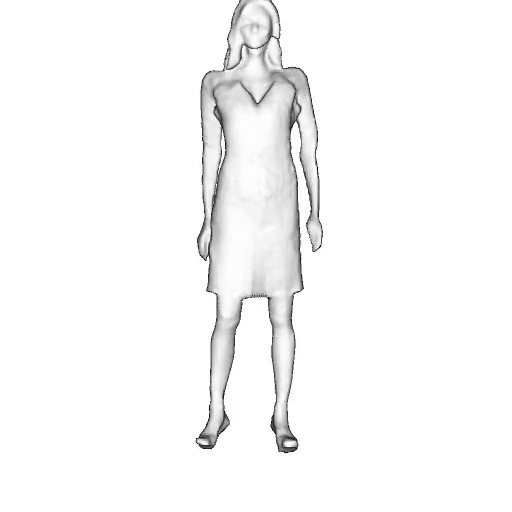
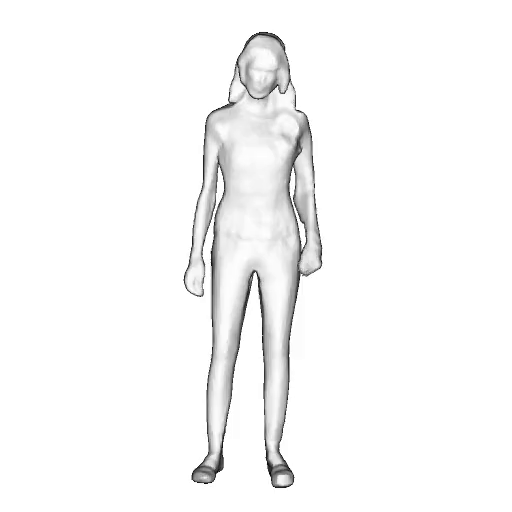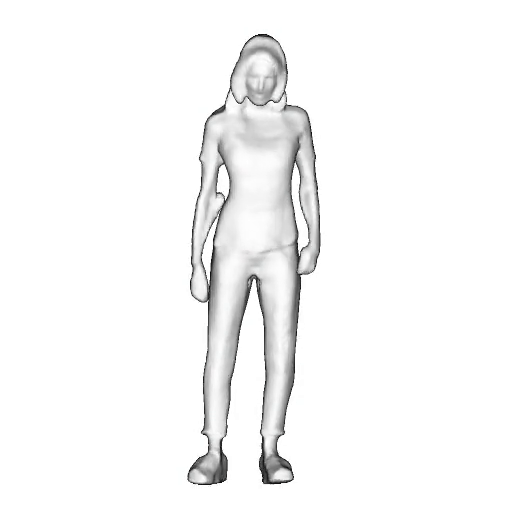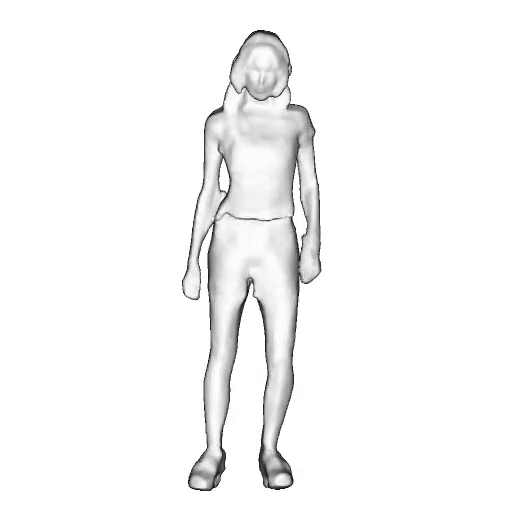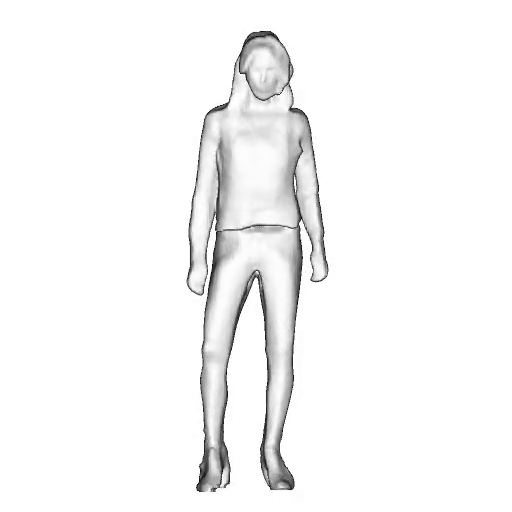
While progress in 2D generative models of human appearance has been rapid, many applications require 3D avatars that can be animated and rendered. Unfortunately, most existing methods for learning generative models of 3D humans with diverse shape and appearance require 3D training data, which is limited and expensive to acquire. The key to progress is hence to learn generative models of 3D avatars from abundant unstructured 2D image collections. However, learning realistic and complete 3D appearance and geometry in this under-constrained setting remains challenging, especially in the presence of loose clothing such as dresses.
In this paper, we propose a new adversarial generative model of realistic 3D people from 2D images. Our method captures shape and deformation of the body and loose clothing by adopting a holistic 3D generator and integrating an efficient and flexible articulation module. To improve realism, we train our model using multiple discriminators while also integrating geometric cues in the form of predicted 2D normal maps.
We experimentally find that our method outperforms previous 3D- and articulation-aware methods in terms of geometry and appearance. We validate the effectiveness of our model and the importance of each component via systematic ablation studies.
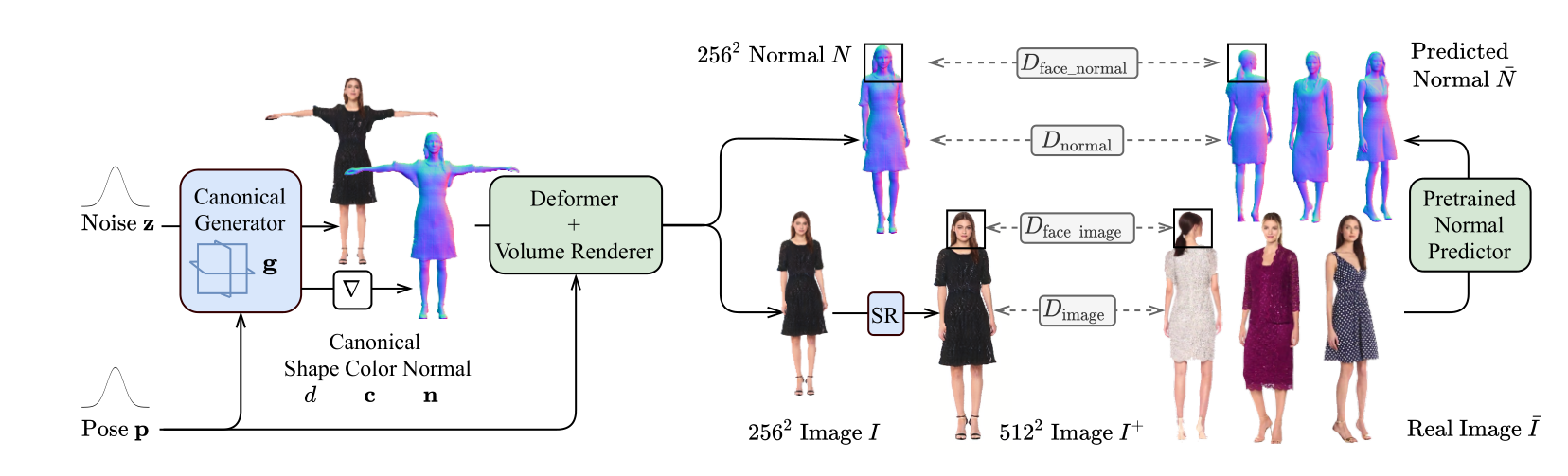
Instead of representing humans with separate body parts, we adopt a monolithic approach that is able to model the human body as well as loose clothing, while adding multiple discriminators that increase the fidelity of perceptually important regions and improve geometric details.
We model the appearance and geometry of 3D humans holistically in a canonical space using a monolithic 3D generator and an efficient tri-plane representation. To enable fast volume rendering, we adapt the efficient articulation module, Fast-SNARF, to our generative setting and further accelerate rendering via empty-space skipping, informed by a coarse human body prior. Finally, the rendered images are lift to high-resolution images.
We propose multiple discriminators to improve geometric detail as well as the perceptually-important face region as we found that a single adversarial loss on rendered images is insufficient to recover meaningful 3D geometry in such a highly under-constrained setting. In addition to an image discriminator operating on the images, we improve geometry by introducing a normal discriminator that compares our rendered normal maps with the normals of real images predicted by an off-the-shelf normal estimator. To further improve the quality of the perceptually important face region, we add normal and image discriminators for the face region.

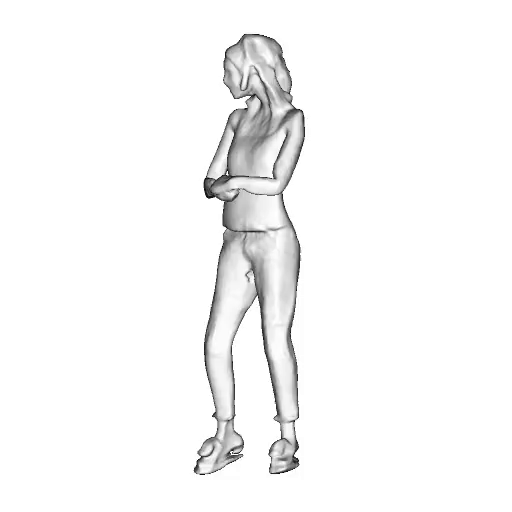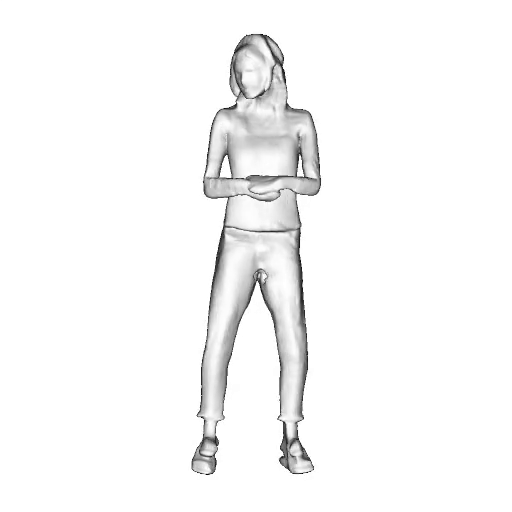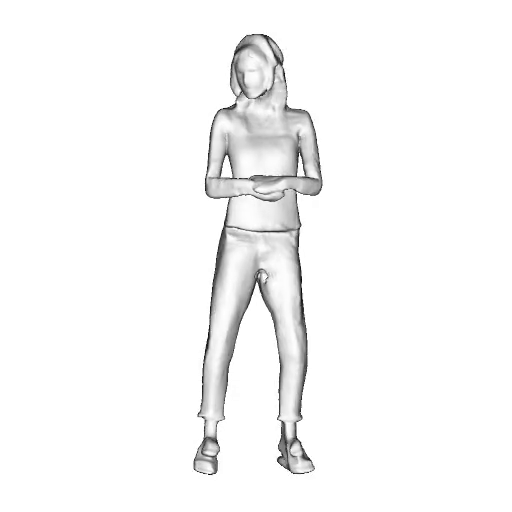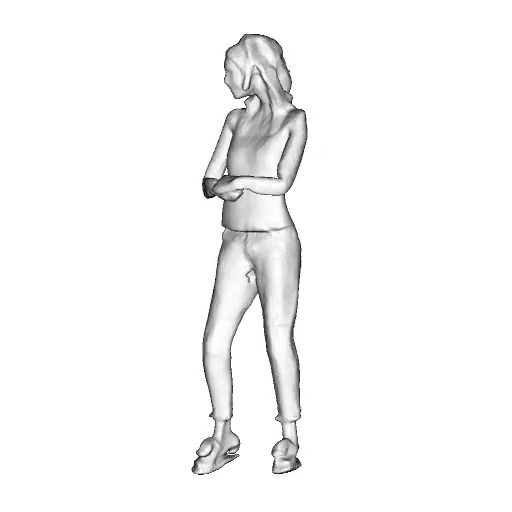

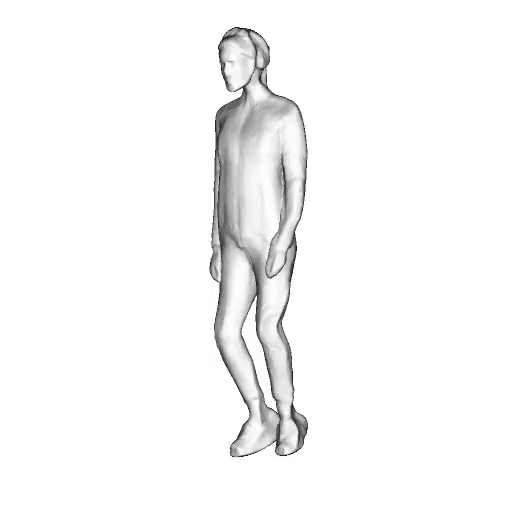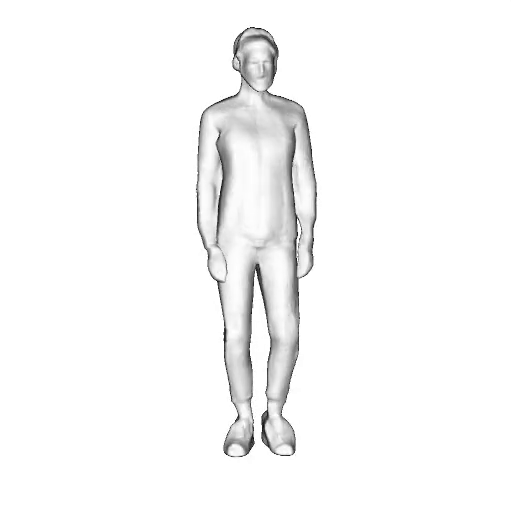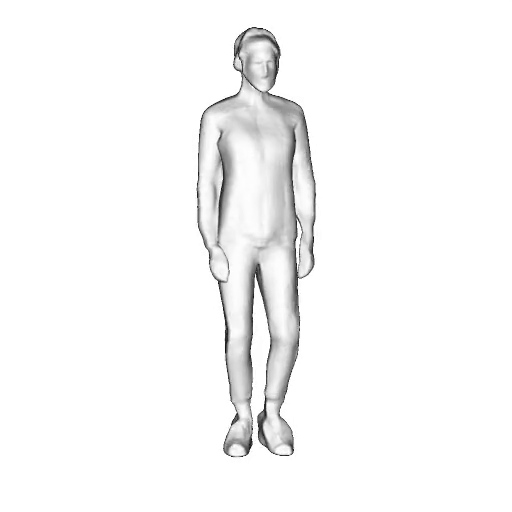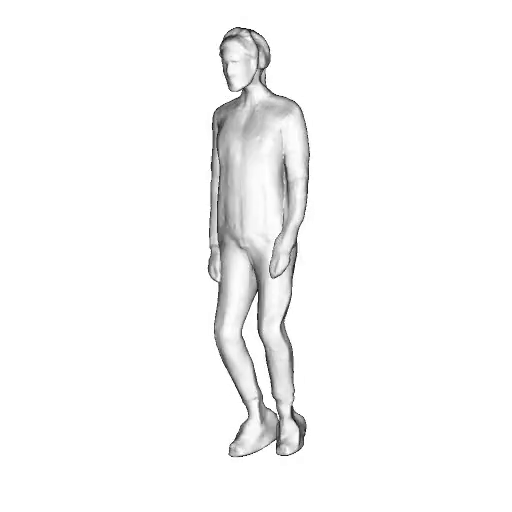

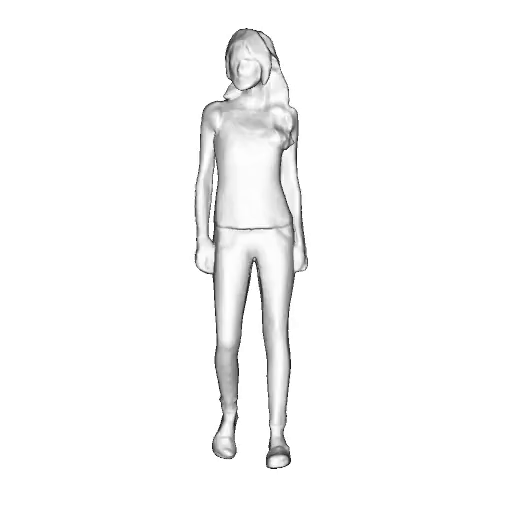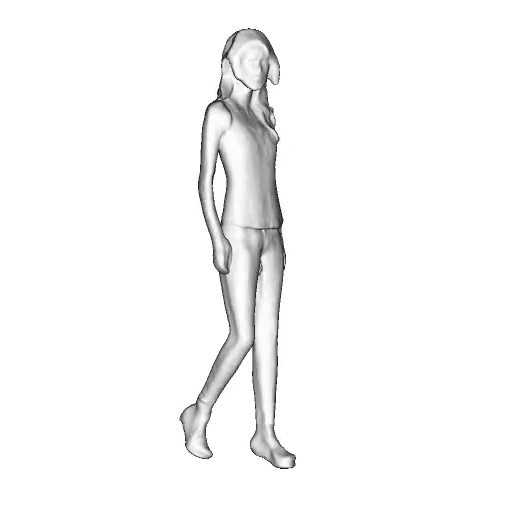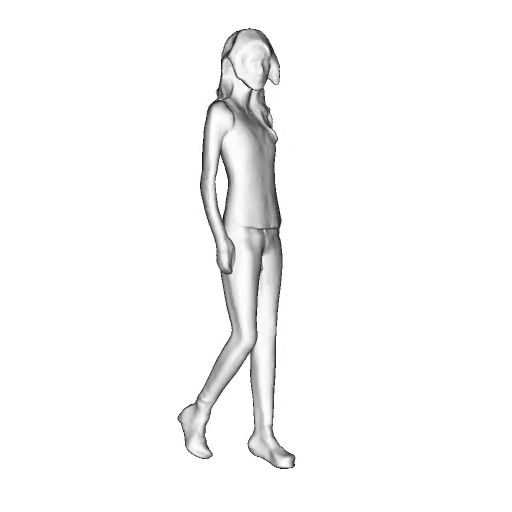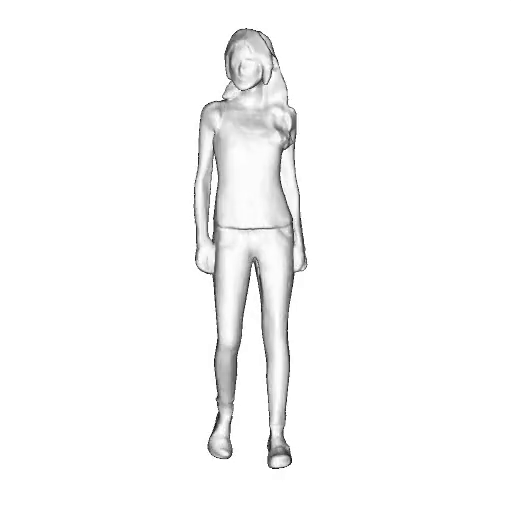


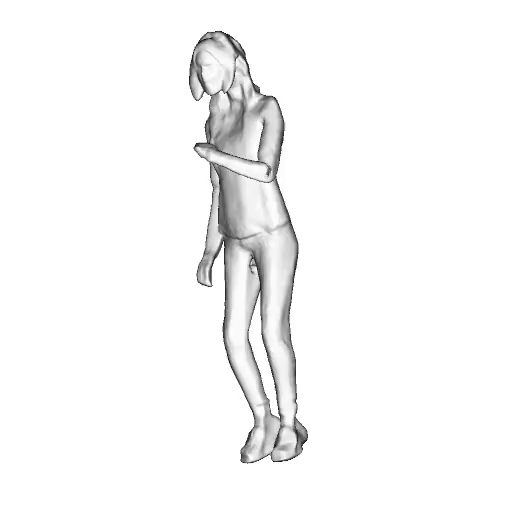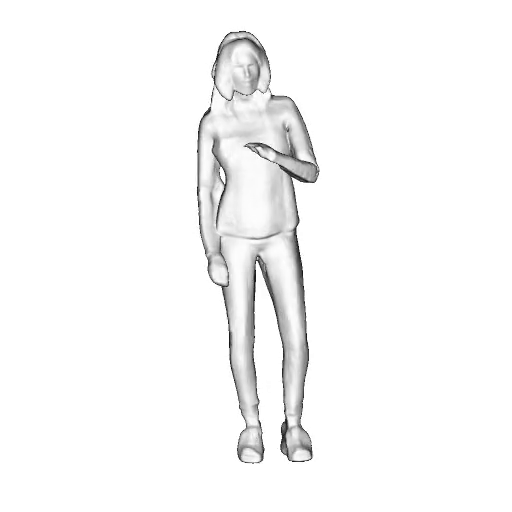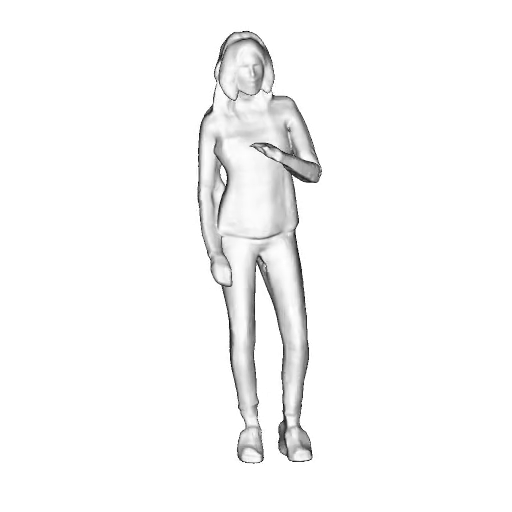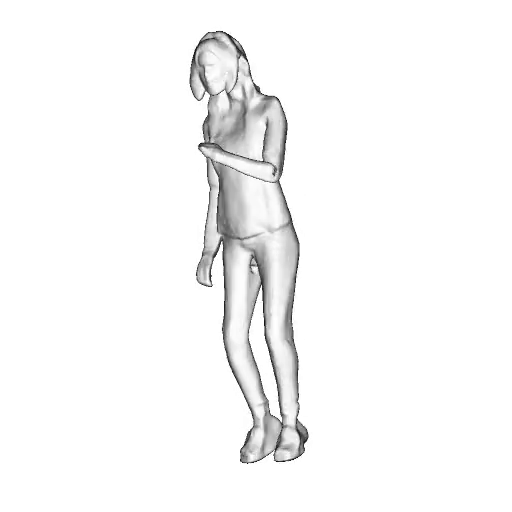

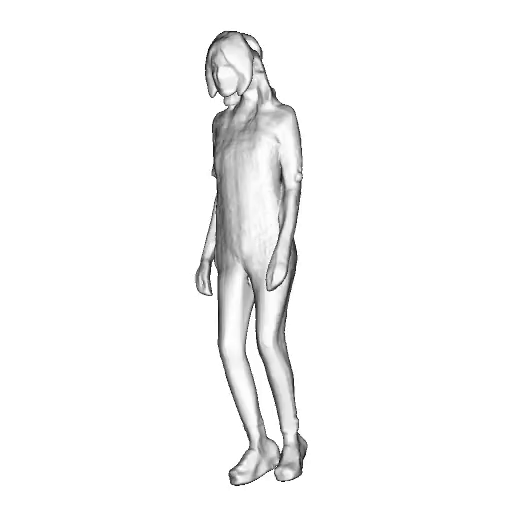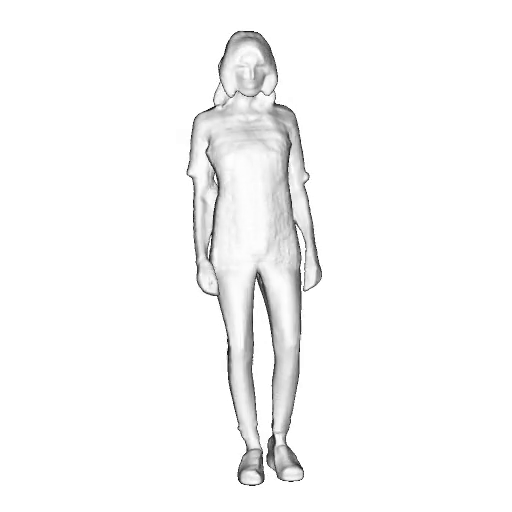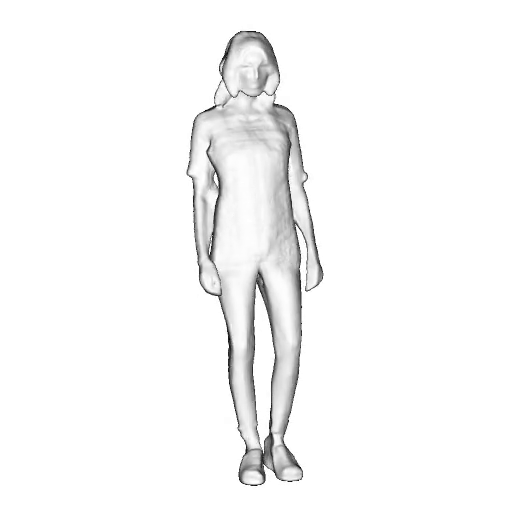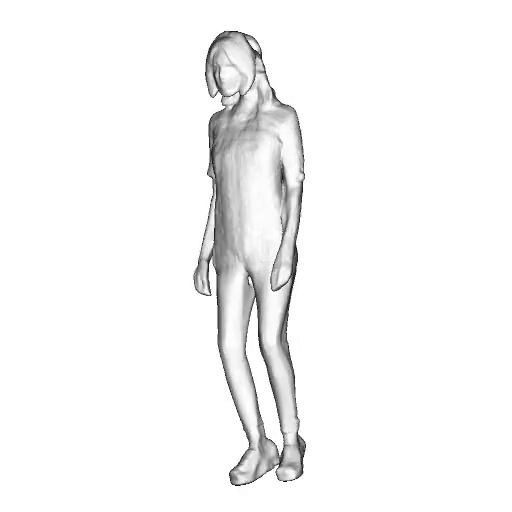

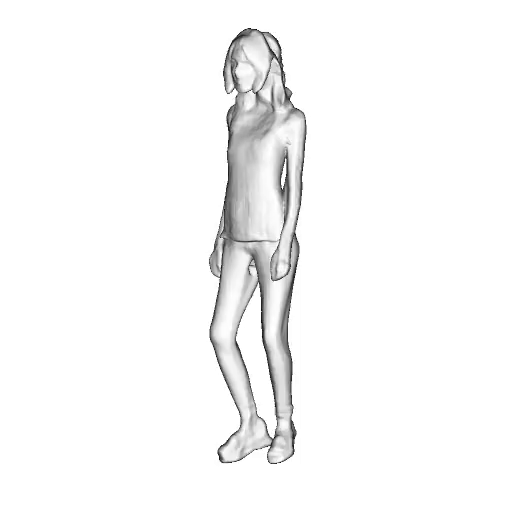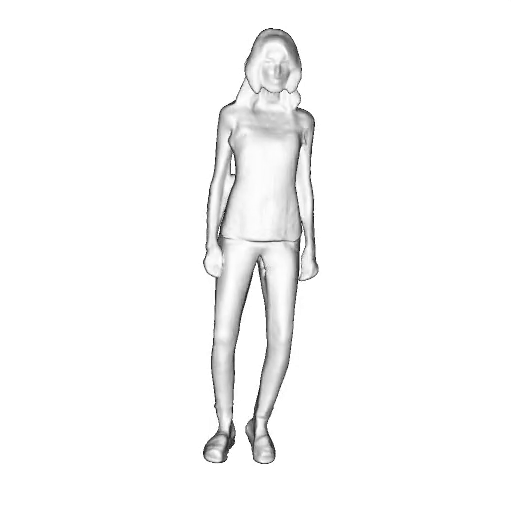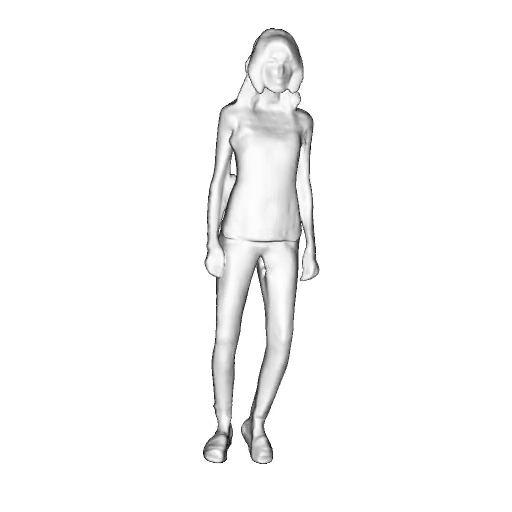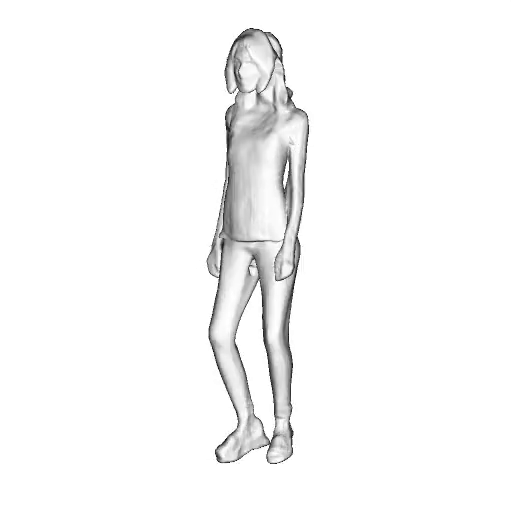

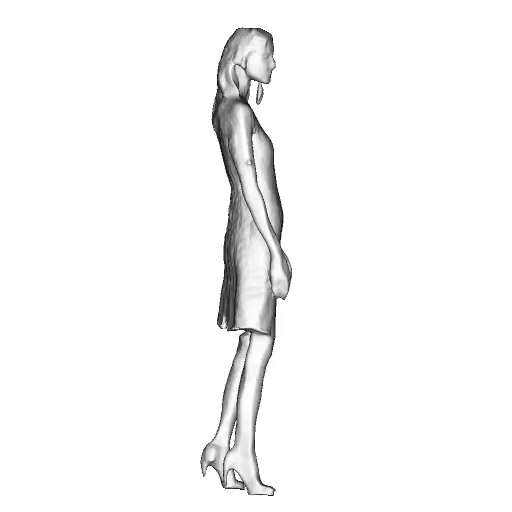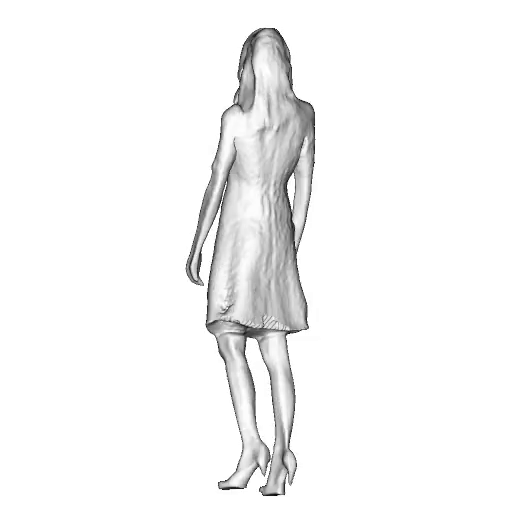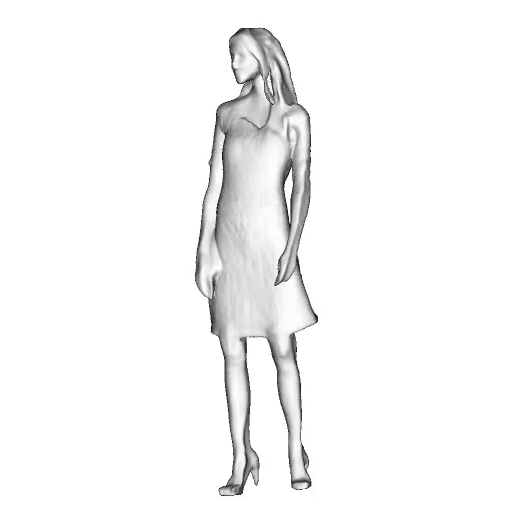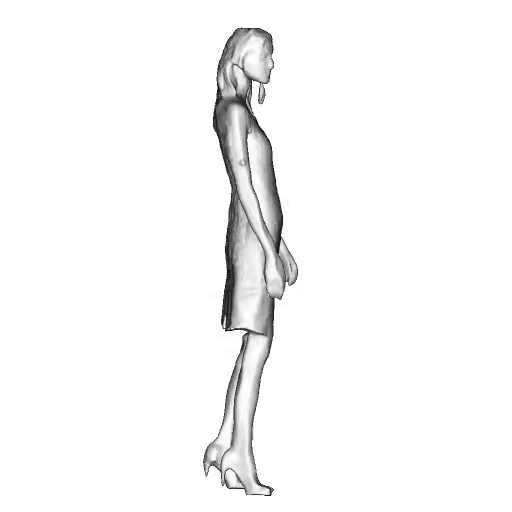



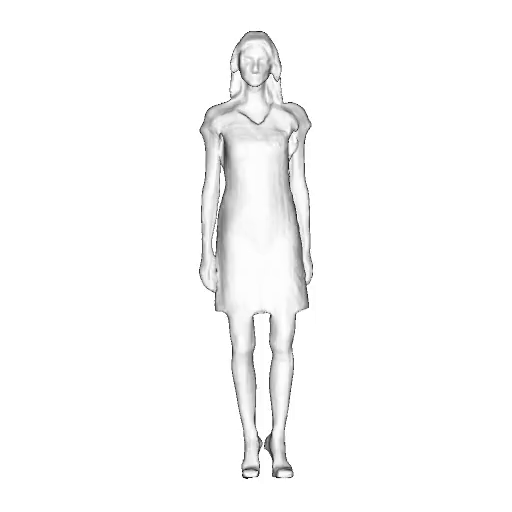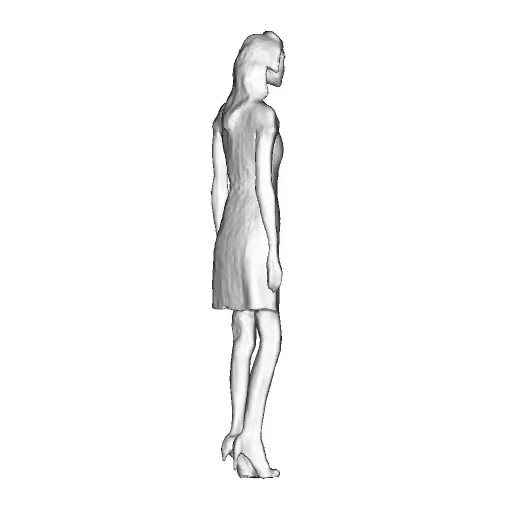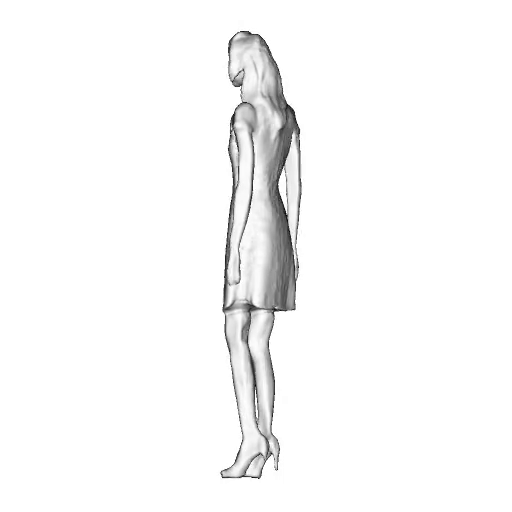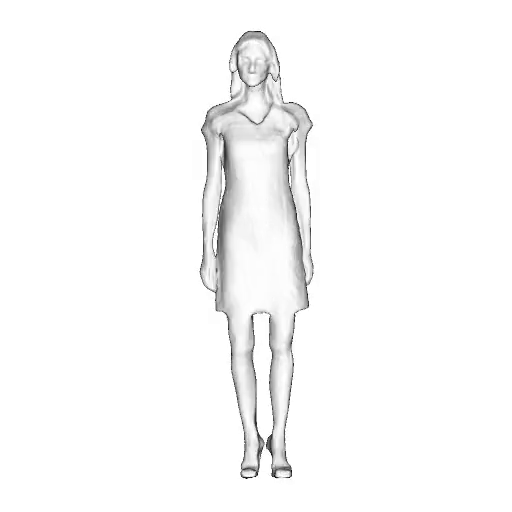

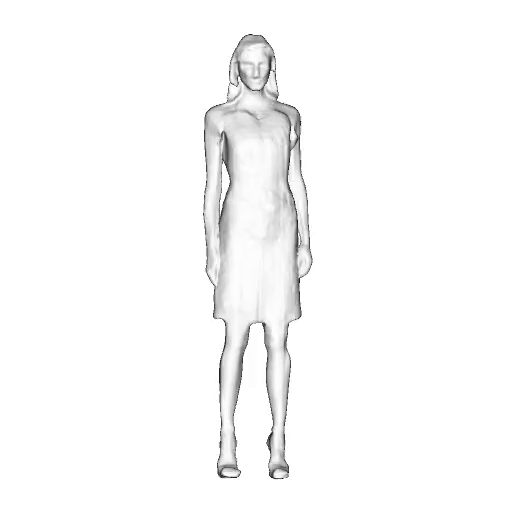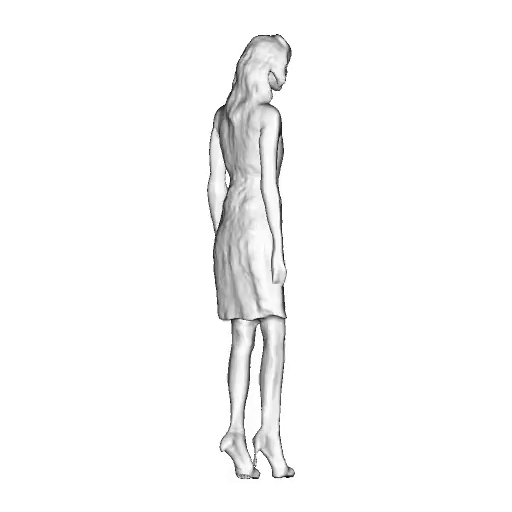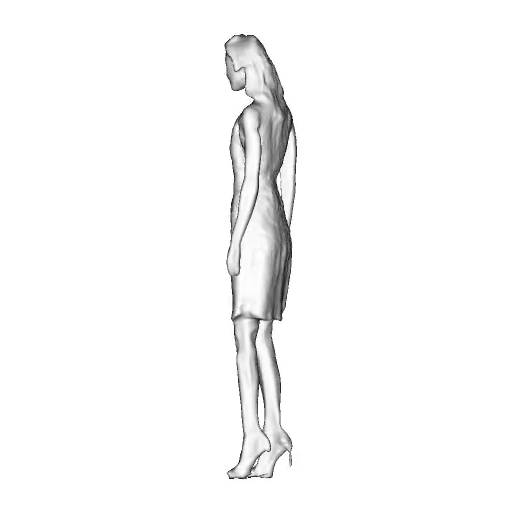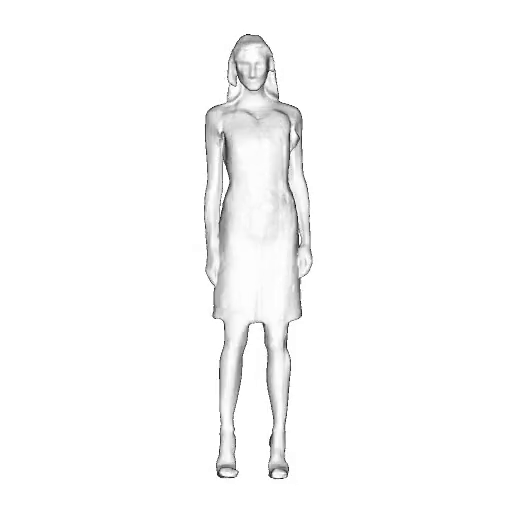




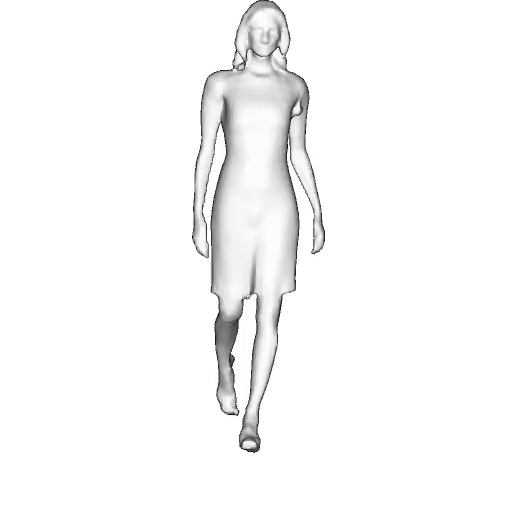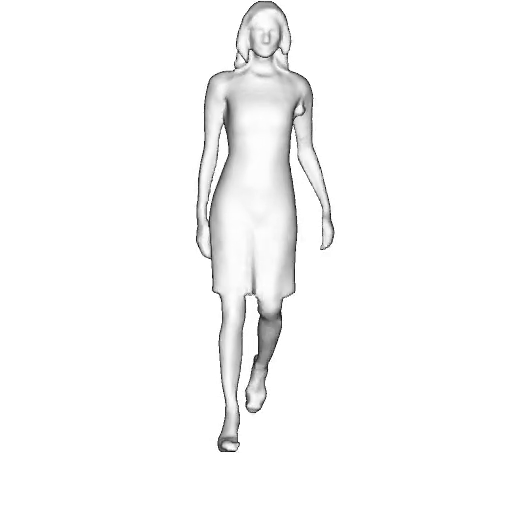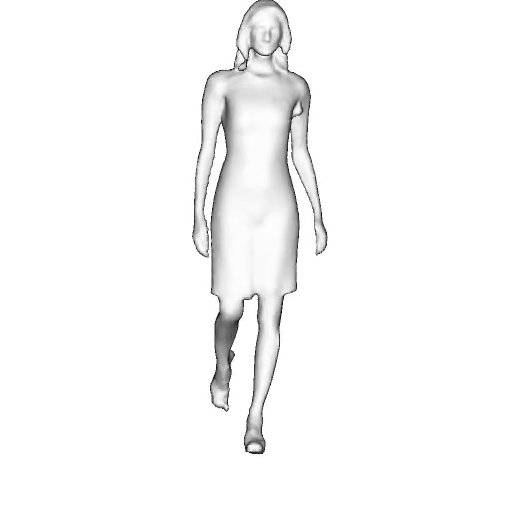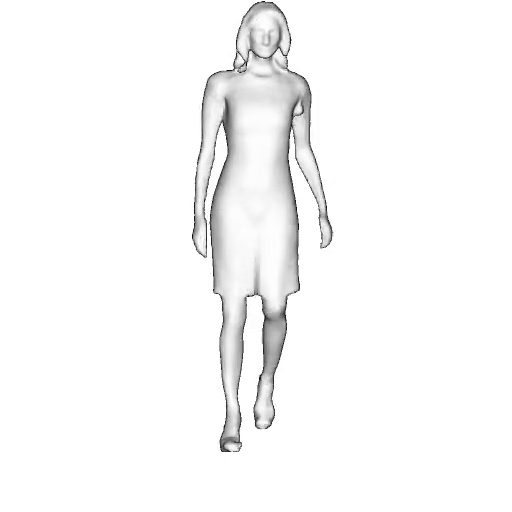

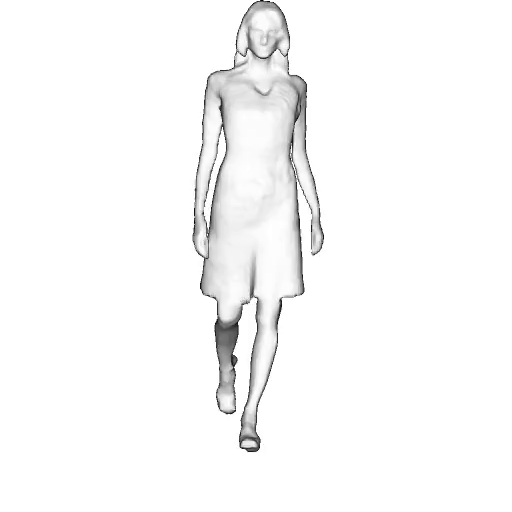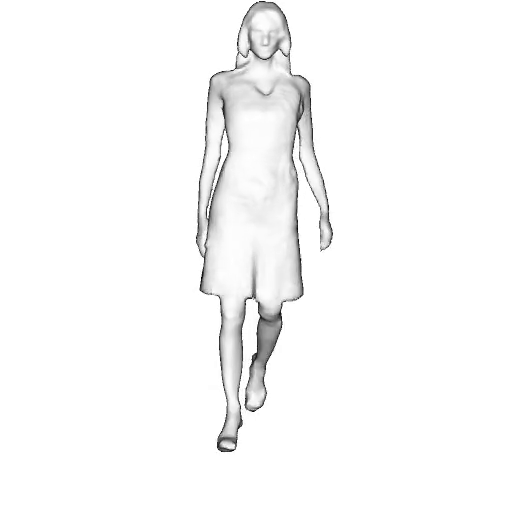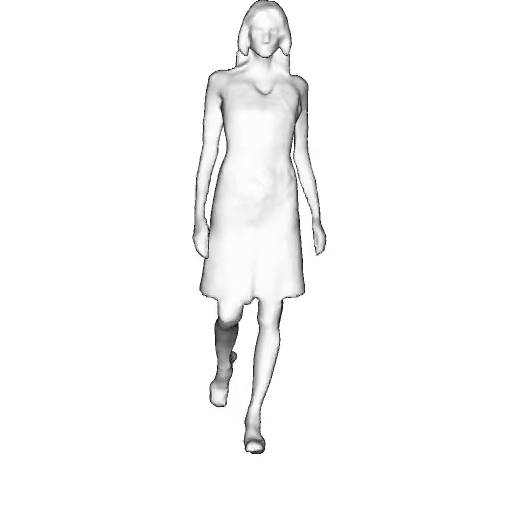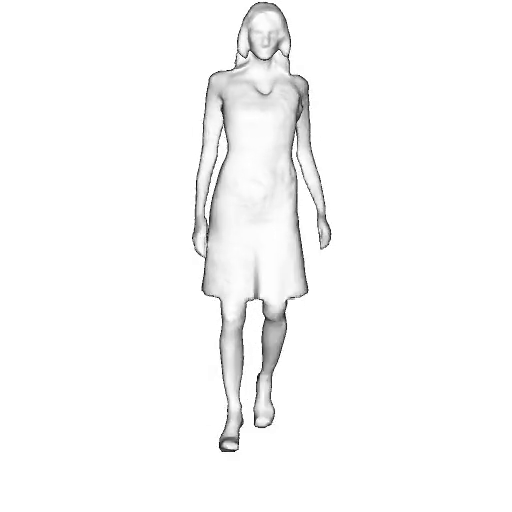

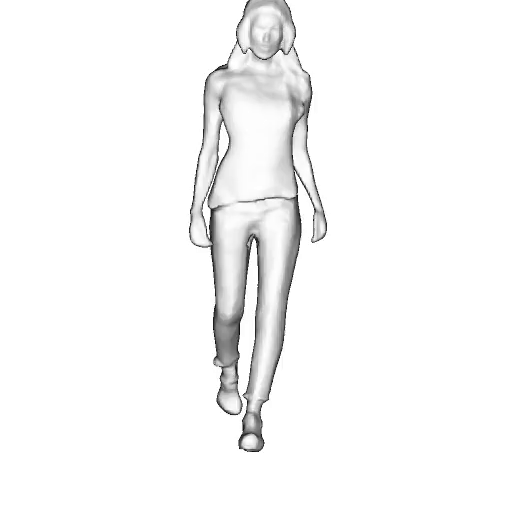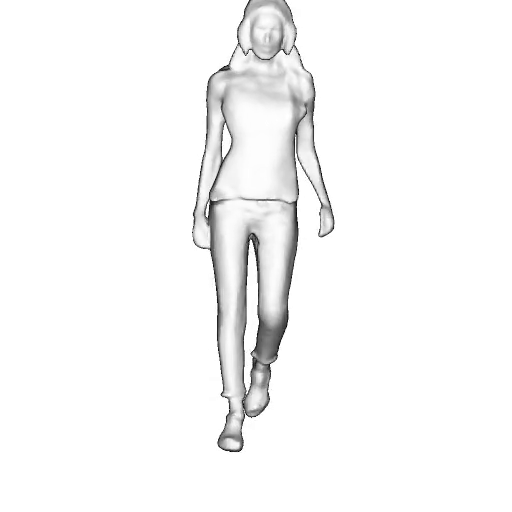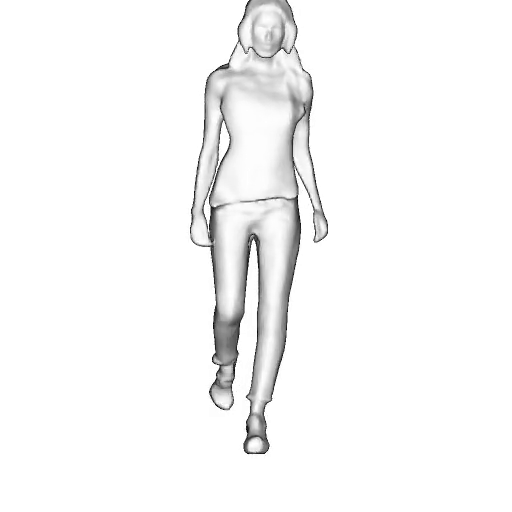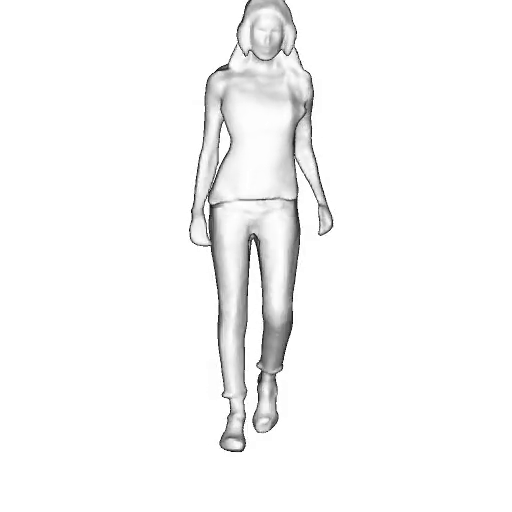

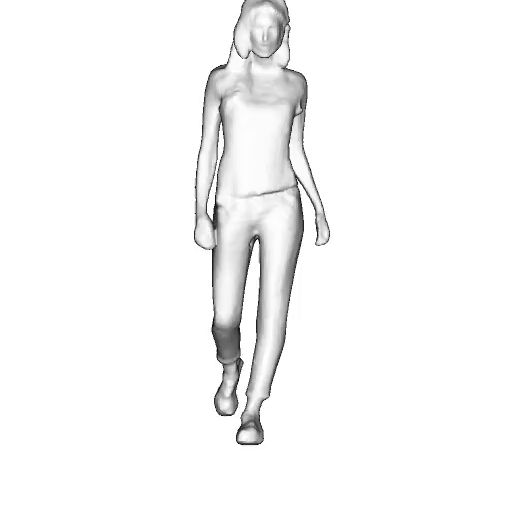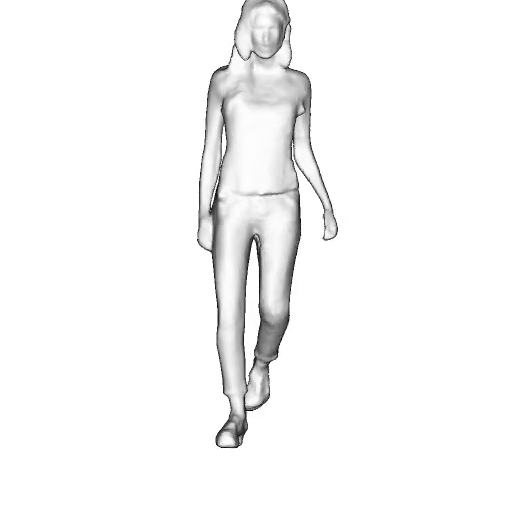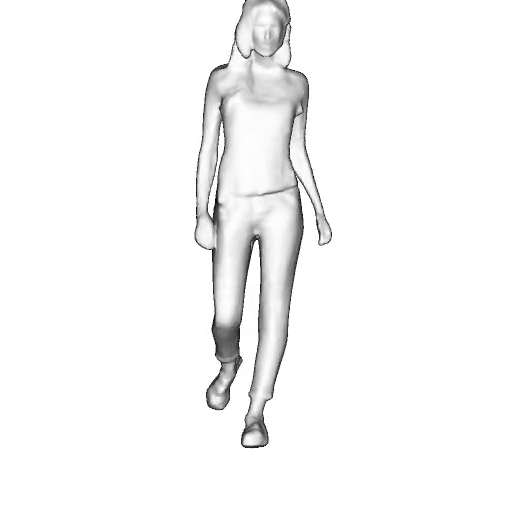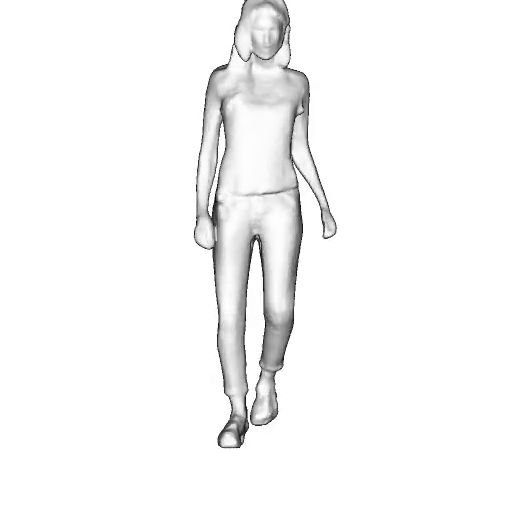



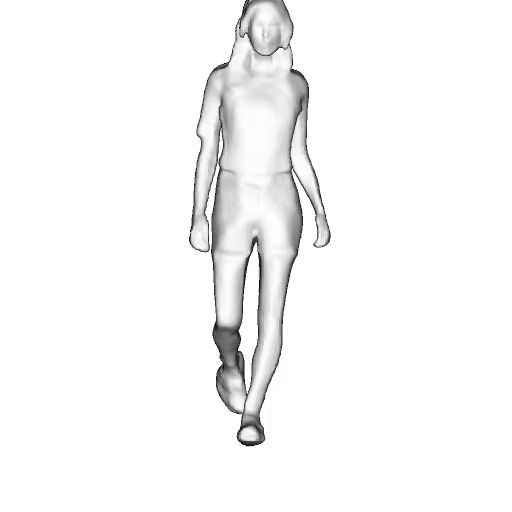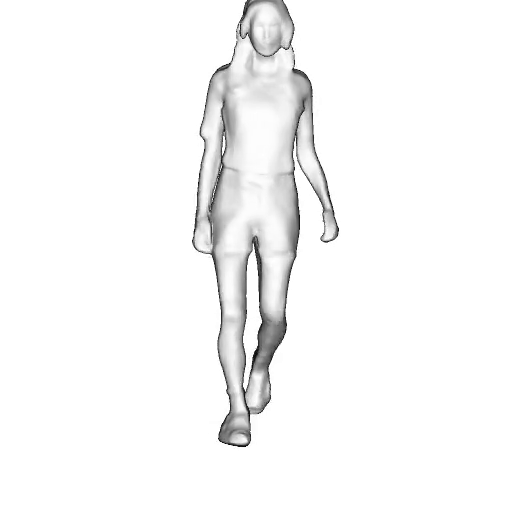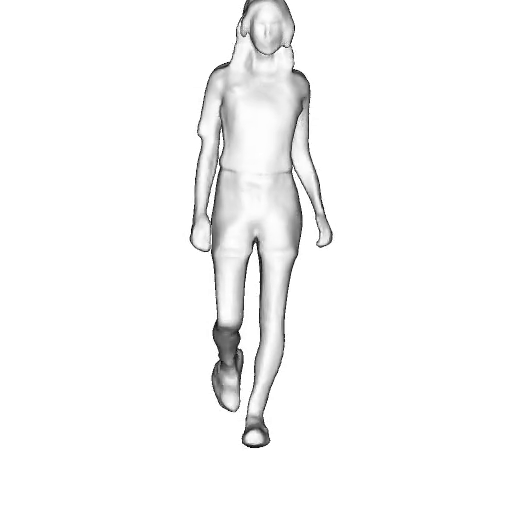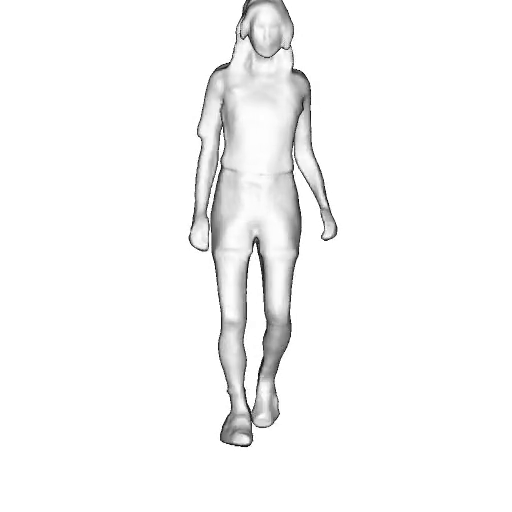



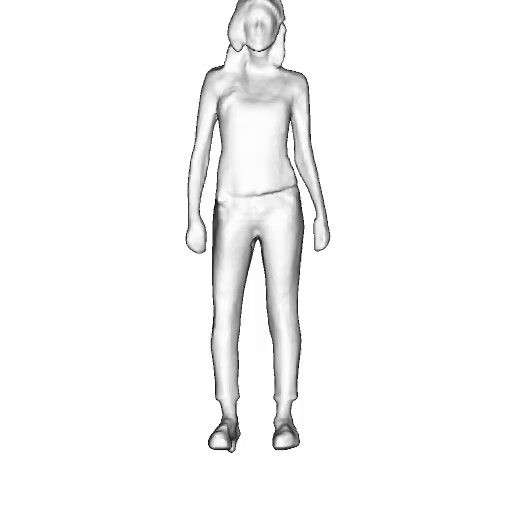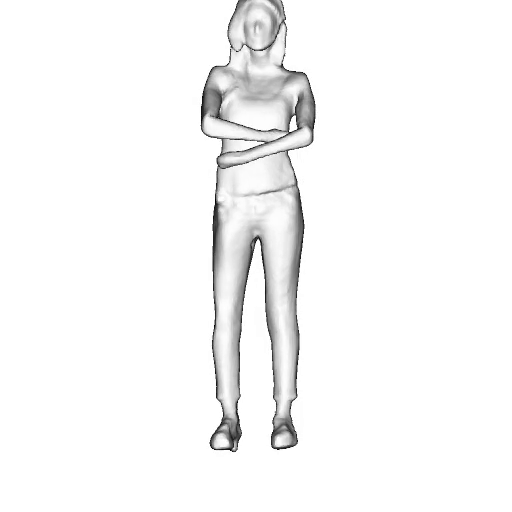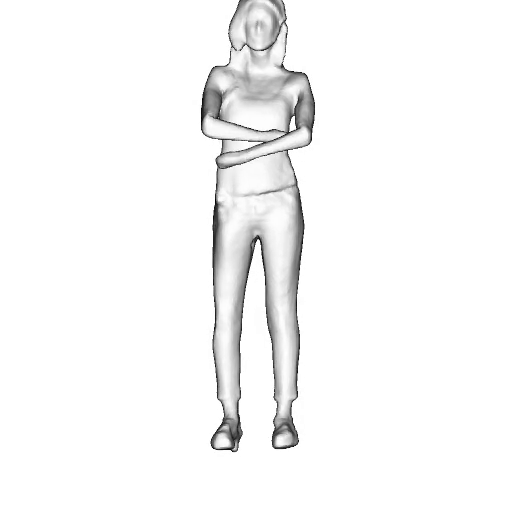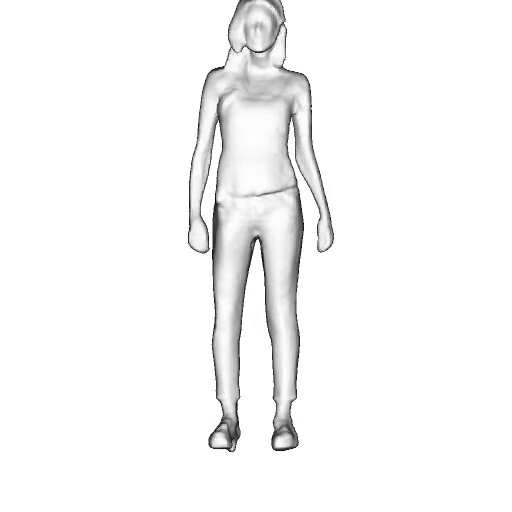

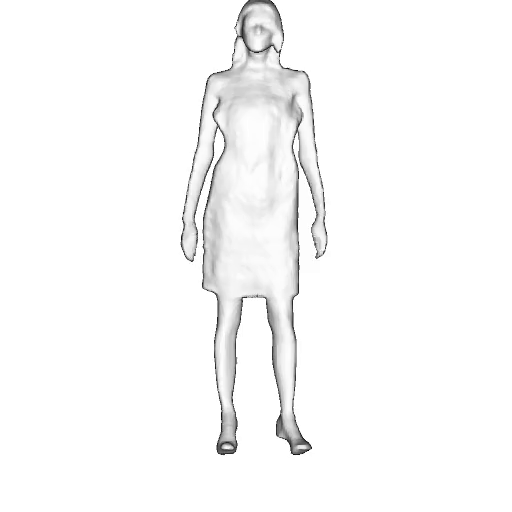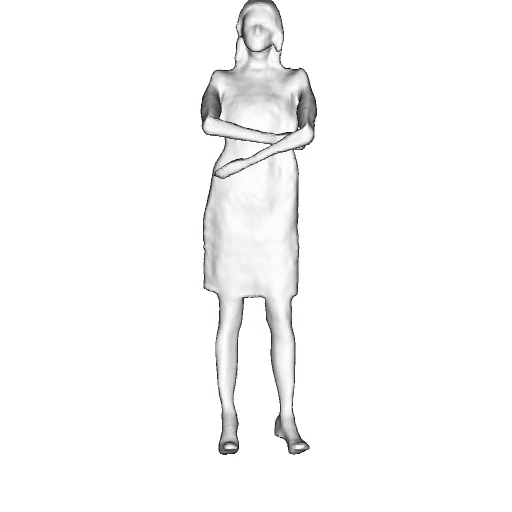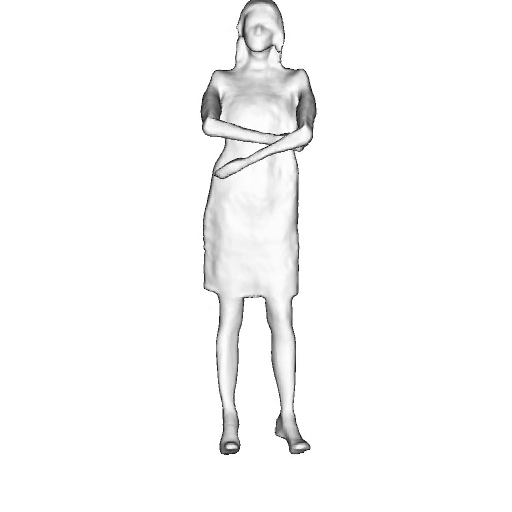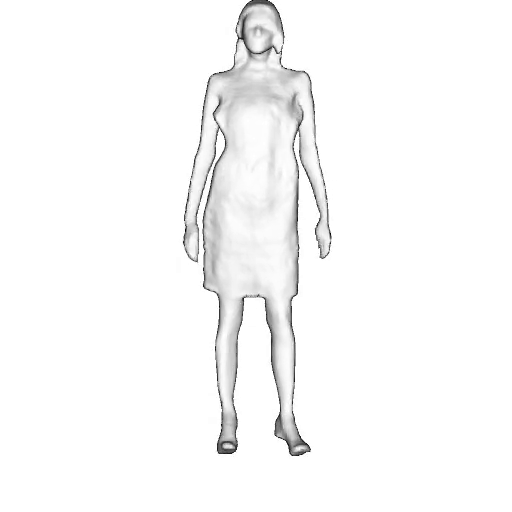





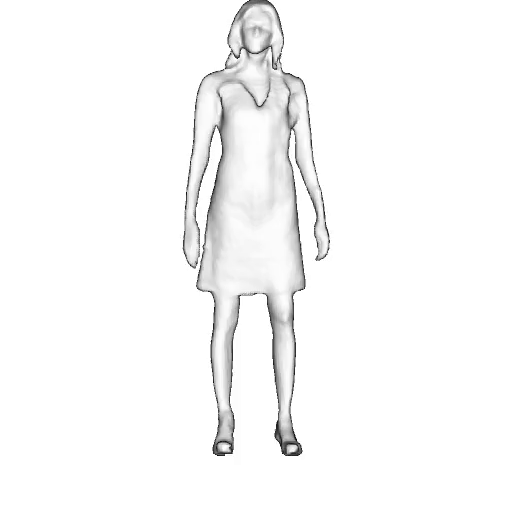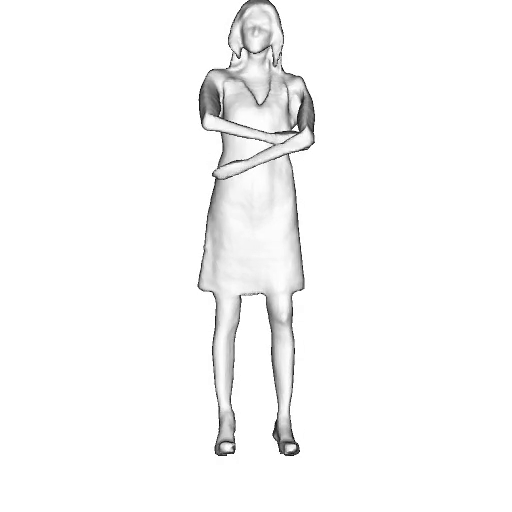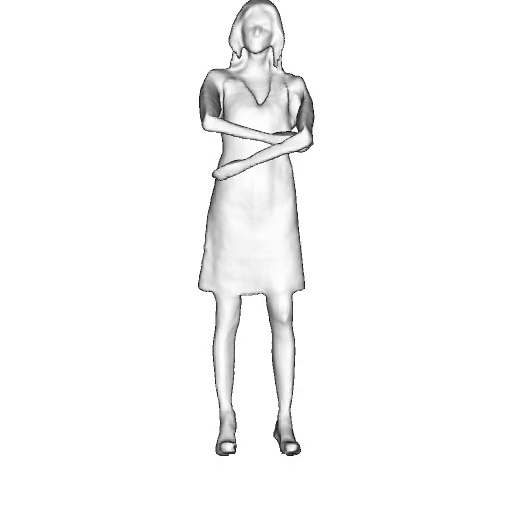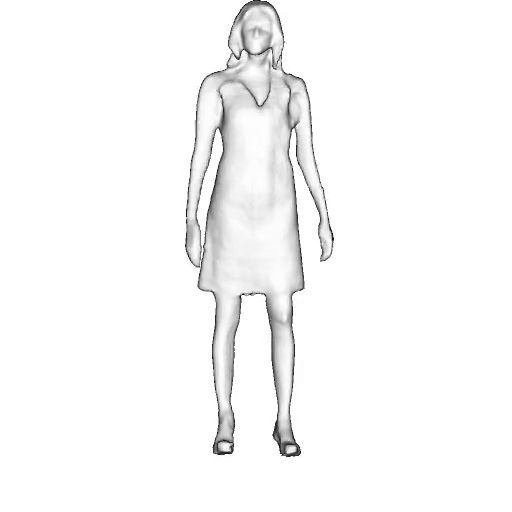



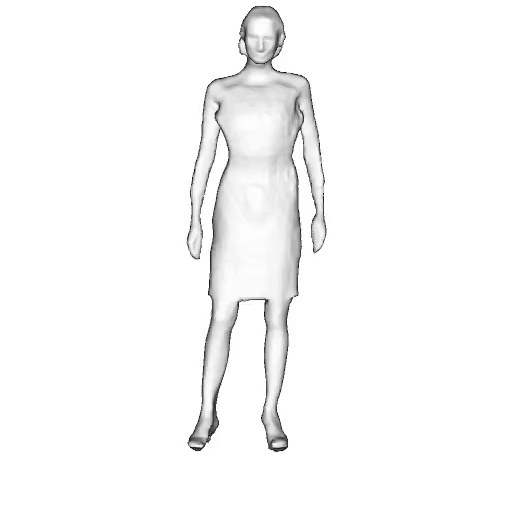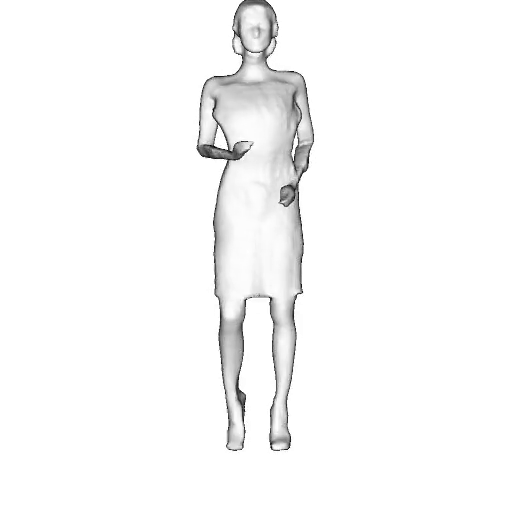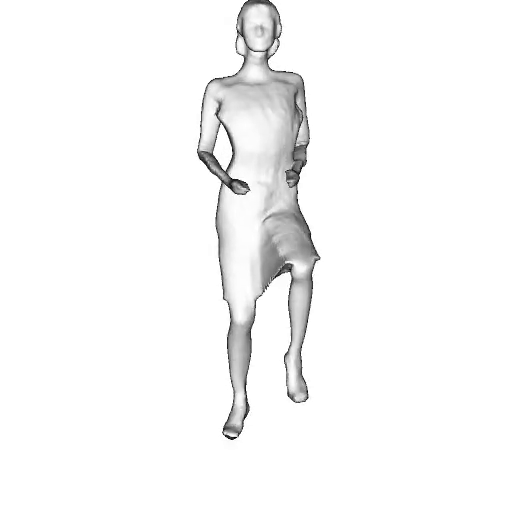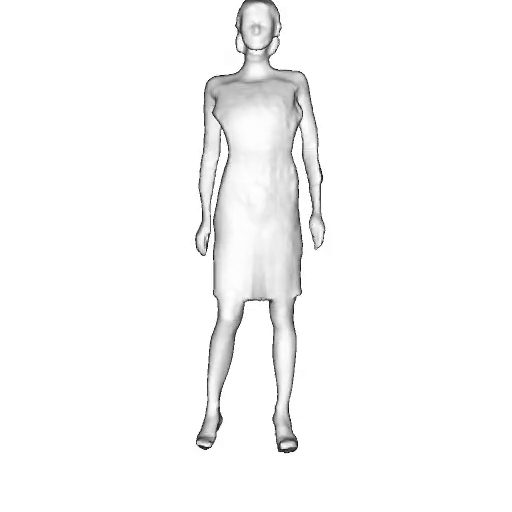







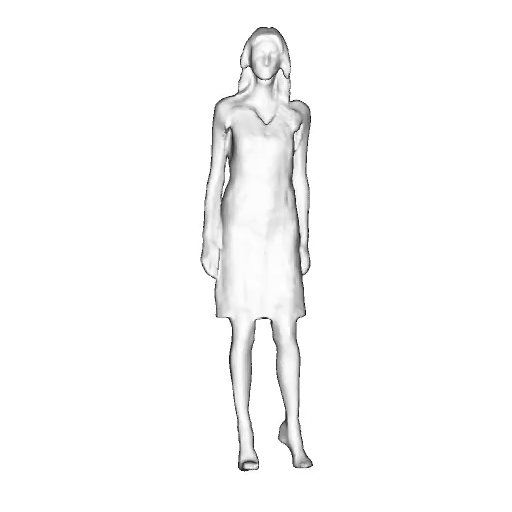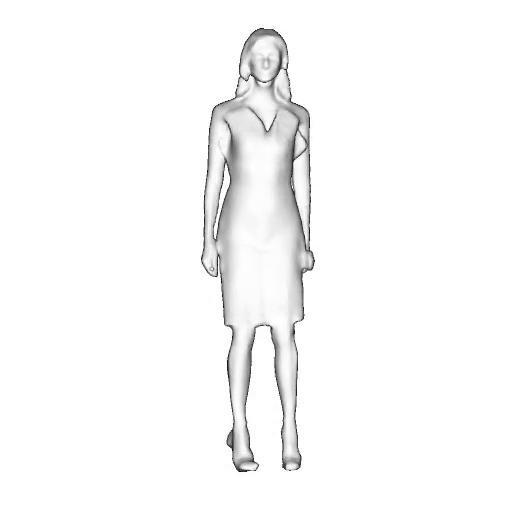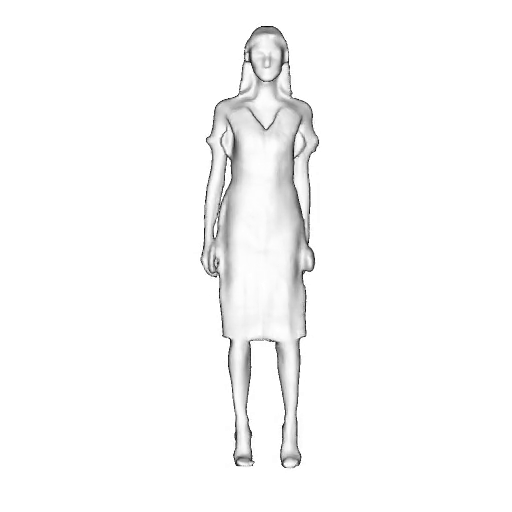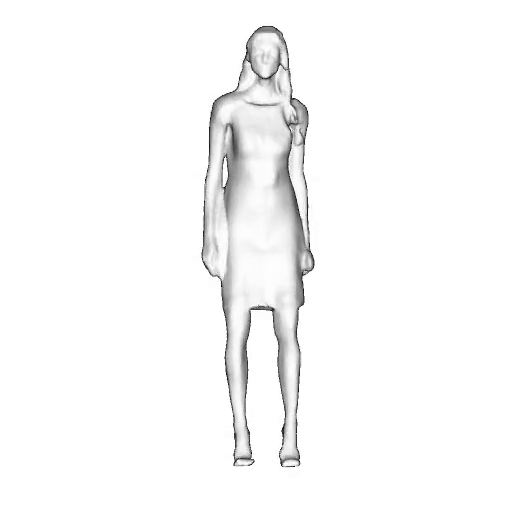



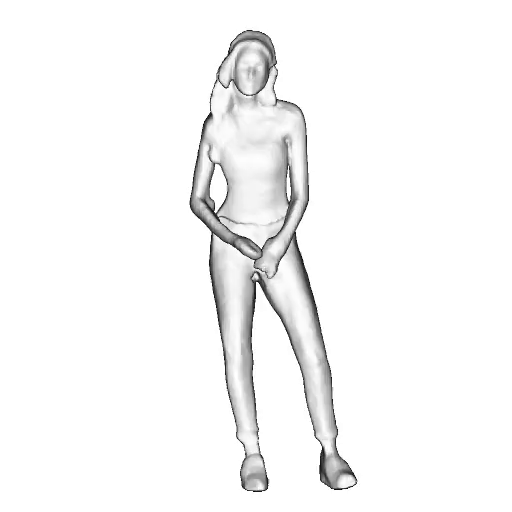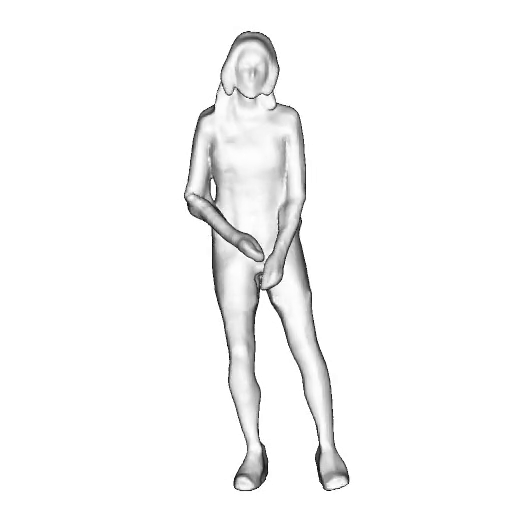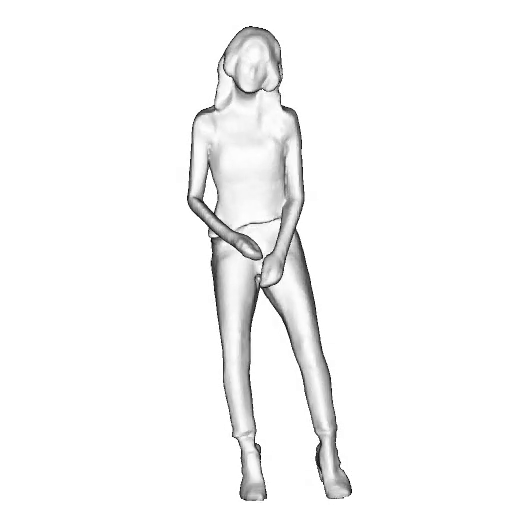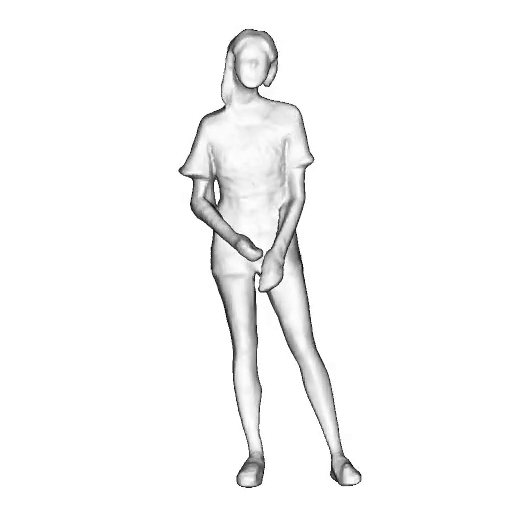

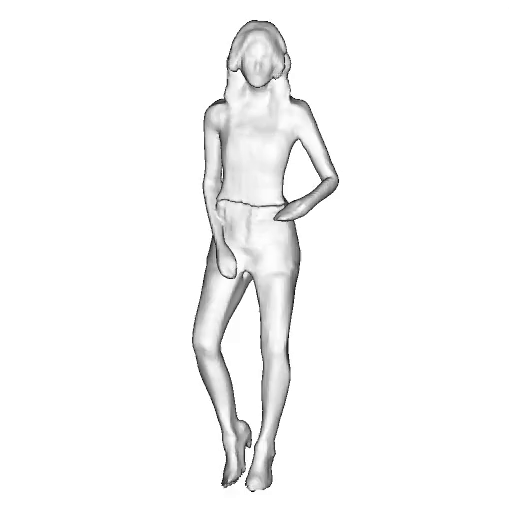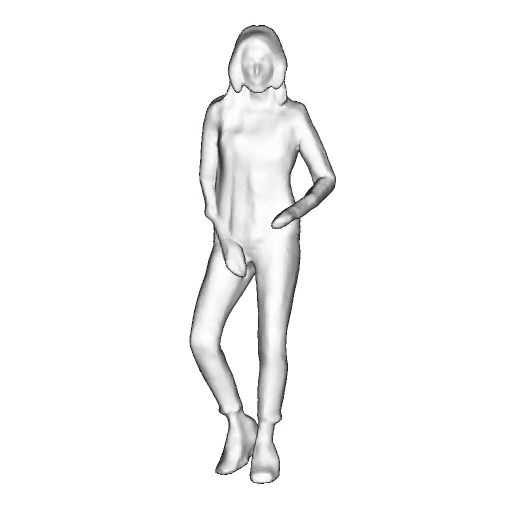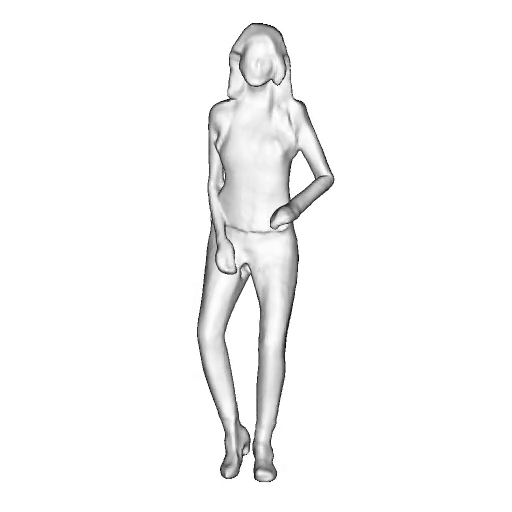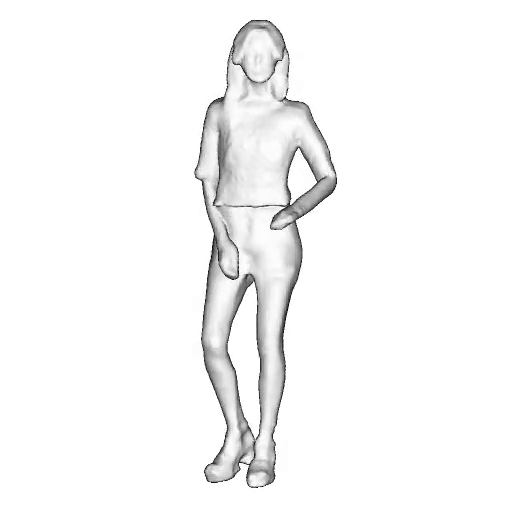
@inproceedings{dong2023ag3d,
title={{AG3D}: Learning to Generate {3D} Avatars from {2D} Image Collections},
author={Zijian Dong, Xu Chen, Jinlong Yang, Michael J.Black, Otmar Hilliges, Andreas Geiger},
booktitle={International Conference on Computer Vision (ICCV)},
year={2023}
}